Customizing Kernels with hipBLASLt TensileLite GEMM Tuning - Advanced User Guide#

Optimizing General Matrix Multiply (GEMM) operations is critical for maximizing the efficiency of AI models on AMD hardware. In our previous blog posts, we explored Offline Tuning, a method for selecting the best-performing kernel from an existing solution pool. For detailed instructions on using hipBLASLt-bench, please refer to hipBLASLt offline tuning part 1 and part 2. Additionally, for a streamlined experience, check out the Day 0 Developer Guide: hipBLASLt Offline GEMM Tuning Script which covers one-click offline tuning. Furthermore, for scenarios requiring dynamic runtime adaptation, developers can explore our recently published blog on hipBLASLt Online GEMM Tuning.
However, for workloads with unique shapes or strict latency requirements, relying solely on pre-existing solutions—whether through offline or online tuning—may not yield the absolute best performance.
This blog focuses on TensileLite Tuning, an advanced optimization approach within hipBLASLt. Unlike standard tuning methods, TensileLite Tuning goes a step further by generating entirely new GEMM kernels and extending the original kernel pool. This allows developers to fine-tune performance parameters specifically for their target problem sizes (M, N, K), ensuring the hardware is utilized to its fullest potential.
Overview of Tuning Approaches#
In hipBLASLt, there are three primary tuning approaches available to optimize GEMM performance on AMD GPUs: Offline tuning, Online tuning, and TensileLite Tuning. Each approach has its own use cases, trade-offs, and workflows. This section provides a brief comparison and offers guidance on when to use each method.
1. Offline Tuning#
Offline tuning selects the best-performing kernel solution from the existing solution pool for a given GEMM problem size (M, N, K) before the application is deployed. During the tuning process, it evaluates candidate solutions and records the optimal solution index in a tuning result text file. At runtime, this index allows the corresponding kernel to be directly dispatched for the specified GEMM shape.
Suitable Scenarios for Offline Tuning#
Situations where tuning time is limited, but stable runtime performance is required.
Production environments where “warm-up” latency at runtime is unacceptable.
Workloads with fixed or known GEMM shapes.
Limitations for Offline Tuning#
May not fully exploit hardware capabilities due to the fixed set of available solutions.
Since it only selects from the predefined solution pool, new or previously untuned GEMM shapes may lack optimized kernels.
2. Online Tuning#
Online tuning works similarly to offline tuning—selecting the best kernel from the existing pool—but it performs this process dynamically at runtime. When a GEMM shape is encountered for the first time, the library benchmarks candidate solutions on-the-fly and caches the index of the best one for subsequent calls.
Suitable Scenarios for Online Tuning#
Applications with dynamic input shapes where pre-calculating every possible dimension is infeasible.
Quick prototyping or development phases where ease of use is prioritized over initial latency.
Limitations for Online Tuning#
Runtime Overhead: There is a significant latency spike during the first execution of a new GEMM shape due to the benchmarking process.
Non-deterministic Timing: Performance may vary during the initial “warm-up” phase until all required shapes have been tuned and cached.
3. TensileLite Tuning#
TensileLite Tuning generates entirely new GEMM solution kernels for the specified problem sizes (M, N, K) by exploring various parameter combinations. By adjusting configuration parameters such as matrix instruction, prefetch global read, prefetch local read, and others, the tuning process produces multiple candidate kernel configurations. The best-performing kernel is then selected and added to the solution pool.
Suitable Scenarios for TensileLite Tuning#
Further optimizing results obtained from offline or online tuning.
Use cases where additional time is available to explore and evaluate different configuration spaces.
Workloads where the existing library does not contain an optimal kernel for a specific shape.
Limitations for TensileLite Tuning#
Time-consuming: Due to the large number of possible parameter combinations, the tuning process can be significantly longer than selection-based tuning.
Complexity: Effective tuning requires domain expertise to navigate the complex interactions between parameters and hardware performance characteristics.
Workflow Comparison#
To better understand where TensileLite Tuning fits into the overall optimization pipeline, Figure 1 breaks down the relationship between these methodologies from two perspectives: procedural flow and optimization scope.
Relative Workflow (a): This illustrates the hierarchical approach to tuning. Developers typically start with Offline Tuning to exhaust the capabilities of the pre-built library. TensileLite Tuning is then applied as an advanced, secondary step specifically for performance-critical shapes that remain bottlenecks, effectively acting as an extension to the standard pipeline.
Relative Search Space (b): This highlights the fundamental difference in potential performance. While Offline Tuning is limited to “selecting” from a finite, pre-compiled solution pool (represented by the smaller circle), TensileLite Tuning “generates” solutions from a vastly larger, nearly infinite parameter space (represented by the encompassing area), allowing it to find optimal configurations that simply do not exist in the standard library.
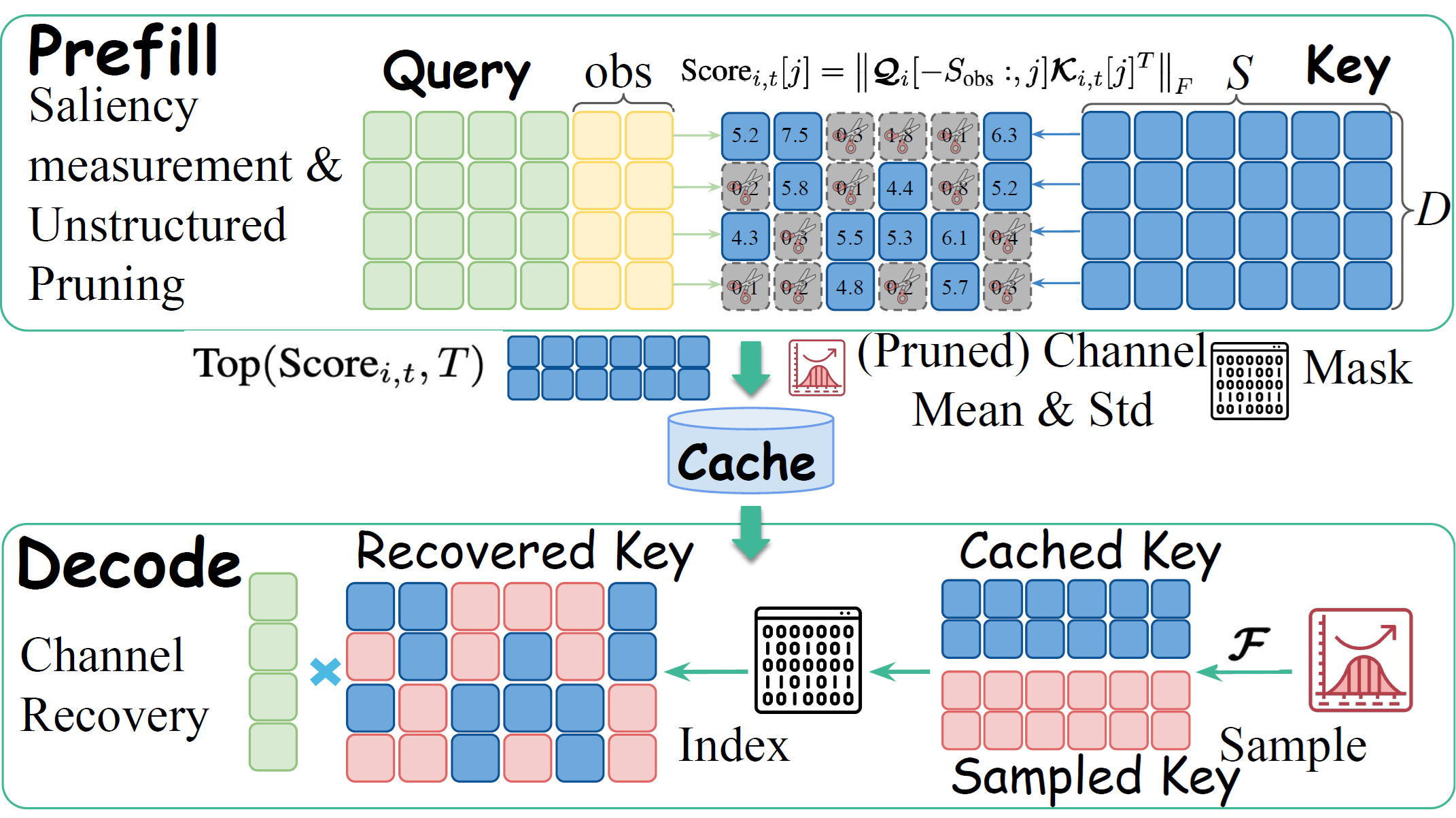
Figure 1. Strategic comparison of tuning methodologies#
Step-by-Step Guide: TensileLite Tuning#
The TensileLite Tuning workflow can be broken down into three major steps: capturing the problem definition, executing the tuning process to find optimal parameters, and integrating the new solution into the library.
Note: All paths and commands in the following steps assume you are operating from the root directory of the cloned
hipBLASLtrepository.
Step 1: Generate Tensile Configuration for a Certain GEMM Operation#
The first step is to identify the specific GEMM problem you want to tune and generate a corresponding Tensile configuration file. This is achieved by running the benchmark tool to produce a log, which is then parsed by a helper script.
1.1 Capture the GEMM Shape#
Execute hipblaslt-bench with your target parameters. By setting HIPBLASLT_LOG_MASK=32, we instruct the library to log the GEMM problem details to a file.
export HIPBLASLT_LOG_MASK=32
export HIPBLASLT_LOG_FILE=./hipblaslt.log
# Example command for a GEMM operation with shape (M=1280, N=32, K=5120)
hipblaslt-bench --api_method c \
-m 1280 \
-n 32 \
-k 5120 \
--alpha 1.000000 --beta 0.000000 \
--transA N --transB N \
--batch_count 1 \
--scaleA 0 --scaleB 0 \
--a_type f16_r --b_type f16_r --c_type f16_r --d_type f16_r \
--scale_type f32_r --bias_type f32_r --compute_type f32_r \
--iters 1 \
--cold_iters 0
Note:
hipblaslt-benchis used here as an example. In practice, you can replacehipblaslt-benchwith the execution of any application or workload (such as an LLM inference engine) that utilizes thehipBLASLtlibrary to capture its specific GEMM shapes.
1.2 Generate Configuration YAML#
Use the tensile_config_generator.py script, located within the source tree at TensileLite/Tensile/Utilities/tensile_generator/, to parse the log and create a tuning_template.yaml file. This file defines the problem sizes and the initial search space for the tuning process.
export GPU_TARGET=gfx942
python tensile_config_generator.py --hipblaslt_log ./hipblaslt.log --tensile_config ./tuning_template.yaml --gpus 4 --iters 100
Result: A
tuning_template.yamlfile containing theProblemSizesmatching your benchmark command.
Step 2: Customize Configuration and Perform TensileLite Tuning#
In this step, the actual tuning occurs. However, before executing the search, it is crucial to understand the search space. TensileLite employs various parameters to define GEMM computing kernels. Because each parameter can simultaneously benefit one aspect of GPU performance while hindering another (e.g., increasing unroll depth improves memory coalescing but increases register pressure), automated tuning is necessary to find the optimal combination.
2.1 Customize Parameter Combinations#
The tuning_template.yaml file defines the search space for these parameters. Below is a breakdown of the key Tensile parameters and their impact on GPU resources:
A. Thread & Workgroup Organization#
These parameters define how the matrix is tiled and distributed across Compute Units (CUs).
WorkGroup (
[dim0, dim1, LocalSplitU]): Defines the size of the workgroup. Proper sizing is critical for occupancy.ThreadTile (
[dim0, dim1]): The size of the tile computed by a single thread.MacroTile: Derived from
WorkGroup * ThreadTile. It represents the size of the matrix block processed by a workgroup. Large tiles improve data reuse but may reduce the number of active waves.WorkGroupMapping: Determines the order in which work-groups compute C. This directly affects L2 cache hit rates by optimizing spatial locality.
B. Loop & Unrolling Control#
These parameters control the instruction pipeline and loop overhead.
LoopUnroll: Defines how many iterations of the inner loop are unrolled.
Impact: Higher unroll factors help load coalesced memory and hide latency but significantly increase register usage (GPRs).
LoopDoWhile: Controls the loop structure (
True=DoWhile,False=While/For).LoopTail: Handles the remaining iterations when the loop count isn’t a multiple of the unroll factor.
DepthU: Derived from
LoopUnroll * SplitU, representing the K-dimension depth per iteration step.
C. Parallelism Strategies (Split-K)#
For shapes with large K dimensions or small M/N, standard parallelism may be insufficient.
LocalSplitU: Splits the summation within a workgroup.
Trade-off: A higher value increases overall GPU occupancy but reduces global data sharing efficiency.
GlobalSplitU: Splits the summation among different workgroups. This launches a second kernel for atomic reduction.
Trade-off: Creates massive concurrency for small-tile/large-K problems but introduces kernel launch and atomic write overheads.
D. Memory Access & Latency Hiding#
Optimizing how data moves from Global Memory to LDS and Registers.
PrefetchGlobalRead: If
True, the outer loop prefetches global data one iteration ahead to hide global memory latency.PrefetchLocalRead: If
True, the inner loop prefetches LDS data one iteration ahead to hide shared memory latency.VectorWidth: Defines the vector load size (e.g., VW=4 loads a
float4).Impact: Higher width improves memory bandwidth utilization by ensuring contiguous memory access.
GlobalReadCoalesceGroupA,B / VectorA,B: Control whether adjacent threads or vector components map to adjacent global read elements. This is vital for maintaining memory coalescing, especially when transposing data.
E. Instruction Configuration#
MatrixInstruction: Specifies the underlying hardware instruction (e.g., MFMA for MI300) and wave tiling parameters (blocks, wave tiles). This ensures the kernel leverages the specific AI accelerators on the GPU.
2.2 Build and Execute the Tuning Workflow#
Once the configuration and parameters are defined, the next phase is to build the necessary tools and execute the tuning process. This involves compiling the rocisa binary and running the Tensile.sh script, which automates the benchmarking of the kernel candidates generated from your parameter search space.
Build the Infrastructure#
First, use CMake to prepare the Tensile environment and generate the shell script.
pip install invoke
cd TensileLite
invoke build-client
Execute the Tuning Script#
Run the generated Tensile.sh script using the configuration file from Step 1. The script will iterate through the parameter combinations, compiling and benchmarking each kernel on the target GPU.
# Syntax: ./TensileLite/build_tmp/Tensile.sh <config_file> <output_directory>
./TensileLite/build_tmp/Tensile.sh tuning_template.yaml tuning_result
Output Location: The results will be saved in the
tuning_resultdirectory.Verification: Upon completion, verify that the YAML file exists within
tuning_result/3_LibraryLogic/. This file represents the successful generation of a new, optimized kernel solution mapped to your specific GEMM shape.
Important: The Tensile tuning process does not support pausing or resuming. If the execution is interrupted for any reason (e.g., user cancellation or system restart), the entire tuning process must be restarted from the beginning.
Note: If the
3_LibraryLogicdirectory or the YAML file is missing after the run finishes, it indicates that the tuning process encountered an error and did not complete successfully.
Step 3: Merge the Newly Generated Kernel and Rebuild hipBLASLt#
The final step is to make the new kernel permanently available to your application. By merging the new logic into the library source and rebuilding, you ensure that the specific GEMM shape will always utilize the optimized kernel automatically, without needing external configuration files or manual solution selection at runtime.
3.1 Merge Logic#
Use the merge.py script provided by Tensile to combine your newly generated tuning results (from Step 2) with the existing library logic. This script effectively “injects” the new kernel solution into the library’s decision-making tree.
python3 ./TensileLite/Tensile/Utilities/merge.py \
./library/src/amd_detail/rocblaslt/src/Tensile/Logic/asm_full/aquavanjaram/gfx942/Equality/ \
./tuning_result/3_LibraryLogic/ \
./library/src/amd_detail/rocblaslt/src/Tensile/Logic/asm_full/aquavanjaram/gfx942/Equality/
Destination Path (1st & 3rd argument): The location in the source tree where the logic files reside. In this example:
./library/src/amd_detail/rocblaslt/src/Tensile/Logic/asm_full/aquavanjaram/gfx942/Equality/.Source Path (2nd argument): The directory containing your new tuning results:
./tuning_result/3_LibraryLogic/.
Critical: Please verify that the destination path exists in your source tree before running the merge command. Path structures may vary slightly depending on the GPU architecture (e.g.,
gfx942).
3.2 Rebuild Library#
Once the logic files are merged, recompile hipBLASLt. The build process will detect the updated logic files and compile the new kernels directly into the library binary.
./install.sh -idc -a gfx942
For more build details, please refer to the hipBLASLt library documentation.
Outcome: After the build completes, the hipBLASLt library is updated. Any application—including hipblaslt-bench or your own AI model—that requests the specific GEMM shape you just tuned will now automatically dispatch the newly generated TensileLite kernel, delivering the optimized performance you sought.
Performance Benchmark#
To demonstrate the effectiveness of the tuning workflows, we evaluated the performance of specific GEMM shapes extracted from real-world production inference workloads. We compared the performance across three distinct stages:
Baseline (Default): The out-of-the-box performance using the default heuristic selection (without any explicit tuning).
Offline Tuning: The performance achieved by selecting the best existing kernel from the solution pool (using
hipblaslt-bench).TensileLite Tuning: The performance of a newly generated, custom-tailored kernel specifically built for the target shape.
Test Environment#
The benchmarks were conducted on the following hardware and software configuration:
Component |
Specification |
|---|---|
GPU |
AMD Instinct™ MI300X |
ROCm Version |
6.4.3 |
hipBLASLt Version |
|
OS |
Linux (Ubuntu 22.04) |
Benchmark Results#
The table below details the latency (microseconds) and throughput (GFLOPS) for all tested shapes. It highlights the incremental gains achieved by moving from the default baseline to offline tuning, and finally to TensileLite Tuning.
Table 1. Performance Comparison: Baseline vs. Offline vs. TensileLite
Shape (M, N, K) |
Precision |
Baseline |
Offline Tuning |
TensileLite Tuning |
Speedup |
Speedup |
|---|---|---|---|---|---|---|
( 3, 200, 64 ) |
f16_r / f32_r |
12.2 / 6.3 |
8.3 / 9.3 |
7.5 / 10.2 |
110% |
162% |
( 3, 400, 64 ) |
f16_r / f32_r |
12.4 / 12.4 |
8.2 / 18.7 |
8.1 / 19.0 |
101% |
153% |
( 3, 800, 64 ) |
f16_r / f32_r |
12.5 / 24.6 |
8.3 / 37.0 |
7.7 / 40.1 |
108% |
163% |
( 3, 1600, 64 ) |
f16_r / f32_r |
12.6 / 48.9 |
8.2 / 74.5 |
7.0 / 87.5 |
117% |
179% |
( 3, 3200, 64 ) |
f16_r / f32_r |
12.7 / 97.0 |
8.4 / 146.7 |
7.9 / 156.0 |
106% |
161% |
( 3, 4800, 64 ) |
f16_r / f32_r |
11.7 / 157.5 |
8.2 / 225.2 |
7.2 / 255.1 |
113% |
162% |
( 3, 9600, 64 ) |
f16_r / f32_r |
18.9 / 195.3 |
8.0 / 458.2 |
7.2 / 510.3 |
111% |
261% |
( 3, 14400, 64 ) |
f16_r / f32_r |
23.2 / 238.7 |
9.1 / 606.0 |
8.8 / 628.8 |
104% |
263% |
( 3, 14592, 64 ) |
f16_r / f32_r |
23.2 / 241.8 |
9.1 / 613.6 |
8.8 / 637.3 |
104% |
264% |
( 3, 14848, 64 ) |
f16_r / f32_r |
23.2 / 245.5 |
9.3 / 613.0 |
8.8 / 646.9 |
106% |
264% |
( 3, 15104, 64 ) |
f16_r / f32_r |
23.3 / 248.7 |
9.2 / 632.6 |
8.8 / 656.9 |
104% |
264% |
( 100, 200, 128 ) |
f16_r / f32_r |
9.4 / 543.4 |
8.1 / 632.9 |
7.7 / 661.5 |
105% |
122% |
( 165, 200, 120 ) |
f16_r / f32_r |
13.9 / 568.7 |
7.8 / 1011.7 |
7.7 / 1034.6 |
102% |
182% |
( 100, 400, 128 ) |
f16_r / f32_r |
9.4 / 1095.0 |
8.0 / 1274.1 |
7.3 / 1401.6 |
110% |
128% |
( 165, 400, 120 ) |
f16_r / f32_r |
10.3 / 1537.0 |
9.2 / 1729.2 |
7.7 / 2045.4 |
118% |
133% |
( 100, 800, 128 ) |
f16_r / f32_r |
9.7 / 2113.3 |
8.1 / 2540.0 |
7.8 / 2626.7 |
103% |
124% |
( 165, 800, 120 ) |
f16_r / f32_r |
12.5 / 2531.6 |
8.8 / 3594.0 |
7.8 / 4079.5 |
114% |
161% |
( 100, 1600, 128 ) |
f16_r / f32_r |
16.9 / 2429.3 |
8.6 / 4740.6 |
7.2 / 5662.3 |
119% |
233% |
( 165, 1600, 120 ) |
f16_r / f32_r |
18.2 / 3475.7 |
12.6 / 5023.5 |
9.0 / 7022.1 |
140% |
202% |
( 100, 3200, 128 ) |
f16_r / f32_r |
17.1 / 4801.5 |
12.3 / 6640.4 |
9.0 / 9149.1 |
138% |
191% |
( 165, 3200, 120 ) |
f16_r / f32_r |
30.9 / 4096.3 |
15.7 / 8063.0 |
12.5 / 10142.7 |
126% |
248% |
( 100, 4800, 128 ) |
f16_r / f32_r |
21.8 / 5642.1 |
15.4 / 7996.7 |
11.7 / 10512.0 |
131% |
186% |
( 165, 4800, 120 ) |
f16_r / f32_r |
37.0 / 5136.7 |
20.4 / 9303.4 |
16.6 / 11453.1 |
123% |
223% |
( 100, 9600, 128 ) |
f16_r / f32_r |
42.8 / 5746.8 |
26.1 / 9425.1 |
19.9 / 12376.2 |
131% |
215% |
( 165, 9600, 120 ) |
f16_r / f32_r |
73.5 / 5171.1 |
36.4 / 10443.5 |
29.8 / 12774.6 |
122% |
247% |
( 100, 14400, 128 ) |
f16_r / f32_r |
89.2 / 4133.3 |
38.8 / 9510.9 |
27.9 / 13213.7 |
139% |
320% |
( 100, 14592, 128 ) |
f16_r / f32_r |
89.2 / 4186.2 |
39.1 / 9547.7 |
28.0 / 13361.0 |
140% |
319% |
( 165, 14400, 120 ) |
f16_r / f32_r |
135.9 / 4196.5 |
51.7 / 11038.8 |
42.3 / 13466.0 |
122% |
321% |
( 100, 14848, 128 ) |
f16_r / f32_r |
89.2 / 4259.3 |
39.3 / 9679.8 |
28.1 / 13527.4 |
140% |
318% |
( 165, 14592, 120 ) |
f16_r / f32_r |
136.0 / 4247.5 |
52.0 / 11105.2 |
42.5 / 13589.2 |
122% |
320% |
( 100, 15104, 128 ) |
f16_r / f32_r |
89.4 / 4327.3 |
39.6 / 9765.6 |
28.2 / 13697.4 |
140% |
317% |
( 165, 14848, 120 ) |
f16_r / f32_r |
136.0 / 4324.6 |
52.8 / 11127.9 |
42.8 / 13733.4 |
123% |
318% |
( 165, 15104, 120 ) |
f16_r / f32_r |
136.0 / 4398.8 |
53.9 / 11105.1 |
43.1 / 13885.7 |
125% |
316% |
Average |
119% |
225% |
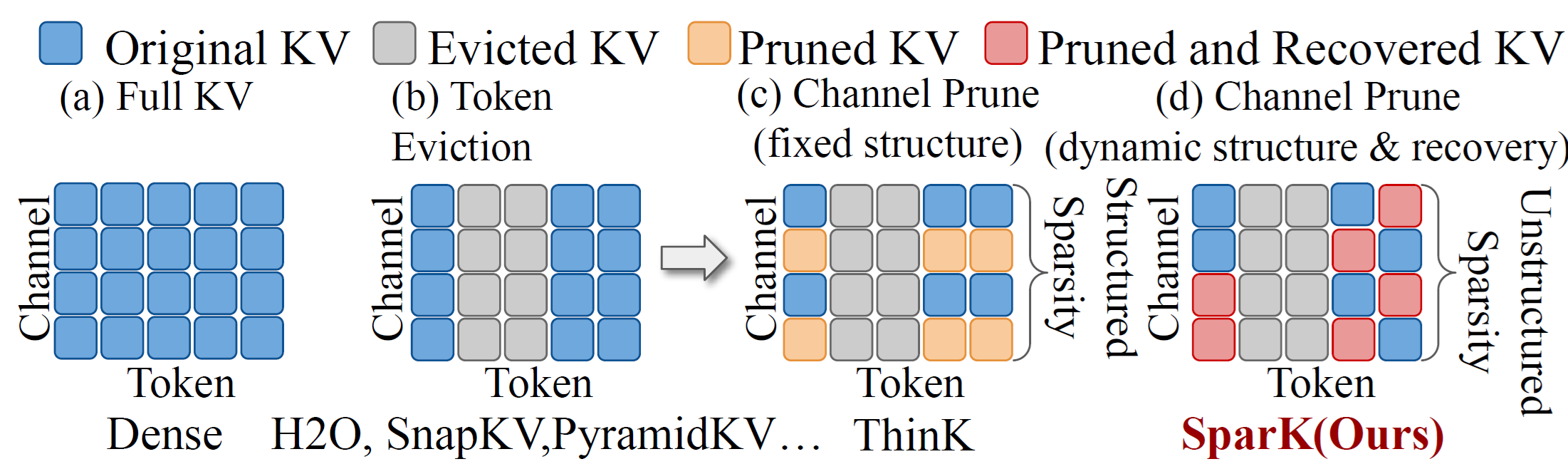
Figure 2. Performance evolution across all tested shapes, showcasing the progression from Baseline to Offline Tuning, and finally to TensileLite Tuning.#
Analysis#
The results from Table 1 and Figure 2 demonstrate a consistent and significant performance uplift across the entire spectrum of GEMM shapes, confirming the efficacy of TensileLite Tuning in optimizing for the AMD Instinct™ MI300X architecture.
The data reveals three key insights regarding the performance gains:
1. Maximizing Efficiency for Small Workloads (M=3)#
For “skinny” matrices (e.g., M=3), typically found in the decoding phase of LLM inference, standard library kernels often incur disproportionate overhead.
Baseline vs. TensileLite: We observe massive speedups ranging from 1.6x to 2.6x. For instance, in the
[3, 14400, 64]case, latency dropped from 23.2 us to 8.8 us.Optimization Mechanism: TensileLite generates kernels with specific tile sizes and thread group dimensions (e.g., MT0/MT1) that perfectly fit the small workload, significantly reducing thread wastage and scheduling inefficiencies compared to generic solutions.
2. Surpassing Pre-compiled Binaries in Medium Workloads#
Offline Tuning typically selects the “best available” kernel from a pre-defined pool, but for irregular shapes, this selection is often suboptimal.
The “Hero” Case: For the shape
[165, 1600, 120], Offline Tuning managed 12.6 us, but TensileLite Tuning further reduced it to 9.0 us. This represents a 1.4x speedup (40% gain) over Offline Tuning and a 2.02x speedup over the Baseline.This result highlights that when GEMM dimensions do not align perfectly with standard block sizes, generating a bespoke kernel is the only way to extract maximum performance.
3. Unlocking Peak Throughput for Large Workloads#
For large N dimensions (N > 9600), TensileLite Tuning redefines the performance ceiling by ensuring better hardware resource utilization.
3x Performance Jump: Across all large shapes, TensileLite delivers an average speedup of ~3.2x vs. Baseline.
Consistent 13+ TFLOPS: While Offline Tuning performance varies, TensileLite consistently pushes throughput to 13.5+ TFLOPS. For example, in
[100, 14592, 128], it achieves a 40% speedup over the best offline kernel. This indicates that custom tuning can better optimize instruction scheduling and memory bandwidth usage, saturating the GPU more effectively than generic kernels.
Conclusion#
Across the board—from an average 119% speedup over Offline Tuning to a staggering 225% over the Baseline—TensileLite Tuning proves to be an essential tool. By generating a custom kernel tailored to the exact problem dimensions rather than selecting a generic one, developers can ensure their applications run at peak efficiency on AMD hardware.
Summary#
GEMM operations lie at the heart of large-scale AI workloads, and in LLMs like Llama 3 or Qwen, they often dominate end-to-end inference latency. While Offline Tuning provides a quick and effective way to select the best pre-existing kernels, it is bound by the limitations of the fixed solution pool.
In this blog, we explored TensileLite Tuning, an advanced methodology that empowers developers to break through those limitations. By generating custom kernels specifically tailored to the unique (M, N, K) dimensions of a workload, TensileLite Tuning allows for:
Precise Optimization: Targeting specific hardware characteristics (such as wave occupancy and LDS usage) for irregular or critical matrix shapes.
Gap Closure: Creating high-performance solutions where generic library kernels might fall short.
Permanent Improvement: Merging these custom solutions back into the library ensures that the performance gains are locked in for all future deployments.
As demonstrated in our benchmarks, the progression from Baseline to Offline Tuning, and finally to TensileLite Tuning, represents a clear path to maximizing hardware efficiency. For developers seeking to squeeze every drop of performance from AMD Instinct GPUs, mastering this advanced tuning workflow is an essential skill.
Acknowledgement#
We would like to express our thanks to our colleagues Brian Chang, Eveline Chen, Bobo Fang, Bill Ku, Han Lin, Kaiping Lu, and Menghsuan Yang for their insightful feedback and technical assistance.
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.