Developers - Applications & Models#

Building a High-Performance Video Inference Pipeline with ROCm Libraries Using C/C++
Learn how to build a powerful, GPU-accelerated video analytics pipeline with ROCm, combining rocDecode for fast hardware video decoding and MIGraphX for efficient AI-powered analysis and inference.

GEAK V3: Agent-Driven, Repository-Level GPU Kernel Optimization across HIP, Triton, and FlyDSL on AMD GPUs
Explore GEAK v3: agent-driven, repository-level GPU kernel optimization across HIP, Triton, and FlyDSL on AMD Instinct™ GPUs.

Triton-Based Optimization of Video Sparse Attention on ROCm
Optimize video sparse attention on ROCm with GEAK and linear global context for faster, more stable video generation on AMD GPUs.

Towards Feature Complete Triton Support in JAX-Triton
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.
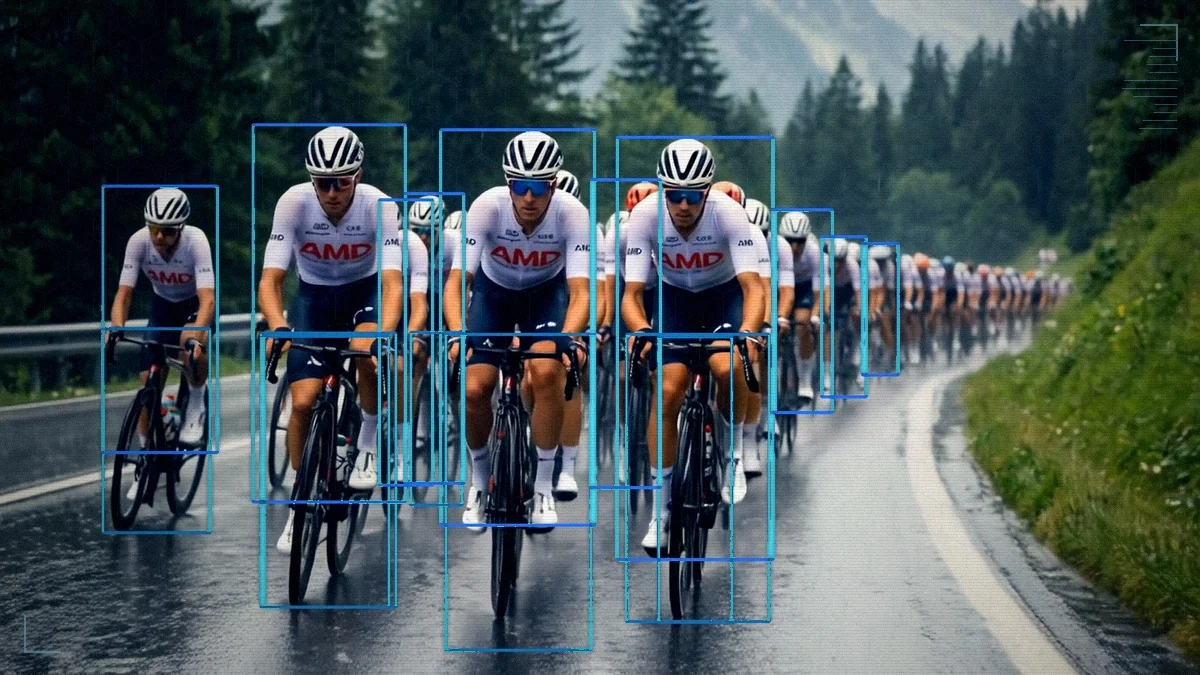
Building a GPU-Resident YOLO26 Object Detection Pipeline on the AMD Radeon™ AI PRO R9700 GPU
Build a GPU-resident object detection pipeline on AMD GPUs with rocDecode, DLPack, and MIGraphX. Frames stay in VRAM end to end.

MXFP6 and MXFP4 Mixed Precision for Accelerating Dense LLMs on AMD Instinct MI355X
W_MXFP4_A_MXFP6 quantization on AMD Instinct MI355X improves LLM throughput and latency while recovering accuracy versus MXFP4.

A Practical Guide to Running LLMs on AMD Radeon™ GPUs
This guide describes how to run LLMs on AMD Radeon™ GPUs using a range of partner frameworks, tools, and runtimes, with step-by-step setup instructions and performance optimization tips.

Efficient and Portable 3D Explorable World Generation on AMD GPUs
Learn how to run Matrix3D world generation on AMD GPUs more smoothly and efficiently.

Utilizing AMD Schola and UnrealRoboticsLab with AMD ROCm™ Software to Train a Robotic Arm
Learn how to combine MuJoCo physics, Unreal Engine, and Schola to train a 6-DOF robot arm with reinforcement learning on AMD hardware.

Customizing Kernels with hipBLASLt TensileLite GEMM Tuning - Advanced User Guide
Master hipBLASLt TensileLite Tuning. Learn to build custom kernels that deliver 150%-250% faster GEMM performance on AMD Instinct™ MI300X GPUs

Training a Robotic Arm Using MuJoCo and JAX on AMD Hardware with ROCm™
A complete guide to training an RL-based pick-and-lift robotic arm in MuJoCo with JAX, running on AMD hardware via ROCm.

Edge-to-Cloud Robotics with AMD ROCm: From Data Collection to Real-Time Inference
This blog demonstrates a comprehensive Edge-to-Cloud robotics AI solution powered by the AMD ecosystem and the Hugging Face LeRobot framework.