ROCm 7.0: An AI-Ready Powerhouse for Performance, Efficiency, and Productivity#

Artificial intelligence now defines the performance envelope for modern computation. In this blog, we introduce the AI-centric ROCm 7.0 designed to help our community directly benefit from this dramatic paradigm shift. ROCm 7.0 delivers a platform purpose-built for the era of generative AI, large-scale inference and training, and accelerated discovery, helping you boost the performance, efficiency, and scalability of your workloads.
ROCm 7.0 raises the bar for end-to-end AI enablement. With breakthrough training and inference performance on the AMD Instinct™ MI350 series, ROCm 7.0 brings together advanced features that span the entire AI stack. Developers can take advantage of greater code portability with HIP 7.0 and enterprise-ready tools that simplify infrastructure management and deployment. In addition, ROCm 7.0 introduces production-ready MXFP4 and FP8 models quantized with AMD Quark, enabling faster, more efficient model delivery at scale.
In this post, we will introduce you to the highlights of this milestone release: the highly performant and refined AI framework ecosystem, the MI350X and MI355X hardware enablement, and the wide array of enhanced tools, libraries, and infrastructure updates included in ROCm 7.0—all designed to help you build, train, and deploy the next generation of AI applications.
AI Ecosystem Highlights#
Alongside ROCm 7.0, we have enabled and optimized leading AI frameworks running atop the ROCm software stack, enabling state-of-the-art (SOTA) model training and inference on Instinct GPUs (see Figure 1, below). Developers can immediately run PyTorch and other leading frameworks with ROCm 7.0, while taking advantage of performance optimizations and tighter integrations across the stack. In the following subsections, we detail the key updates that make this release more robust and scalable for modern AI workloads.

Figure 1. The ROCm 7.0 AI framework ecosystem#

Figure 1. ROCm 7.0 AI framework ecosystem#
AI Frameworks#
As with prior releases, ROCm 7.0 supports PyTorch 2.7 and 2.8, TensorFlow 2.19.1, and JAX 0.6.x, allowing developers to deploy and run models on the latest open-source algorithms.
Key PyTorch features enabled include 3D BatchNorm (F16, BF16, FP32), APEX implementation of the Fused RoPE Kernel, and PyTorch C++, allowing C++ extensions to be compiled via amdclang++. See our release notes for further details.
With ROCm 7.0, ROCm-PyTorch Docker images are now Python wheel-based per GPU architecture, leading to significantly smaller Docker sizes with identical functionality.
With the introduction of the MI350X series, PyTorch, TensorFlow, and JAX provide integrated support for the FP4 data format, a capability natively implemented in this class of GPUs. We have also added support for TF32 tensor operations for the MI350 and MI355 accelerators within PyTorch.
Inference Engines#
With ROCm 7.0, both vLLM and SGLang now support MI350X and MI355X, delivering significantly higher model performance through native FP4 support. Users can access these enhancements today using our latest docker images. The vLLM docker comes equipped with the new v1 engine, boosting real-world serving performance, including TTFT and throughput, with less CPU overhead. Finally, ROCm 7.0 introduces Distributed Inference, enabling Prefill and Decode (PD) disaggregation functionality to Instinct GPUs. This is initially introduced within the SGLang framework, for dense LLMs and MoE models. Read more about how to enable this feature on your cluster in this blog.
AI Model Optimization#
ROCm 7.0 expands Instinct GPUs’ model support far beyond LLMs, with Day-0 support for OpenAI’s open models—gpt-oss-120b and gpt-oss-20b.
In addition, we are releasing production-ready large-scale MXFP4, FP8 models—including DeepSeek R1, Llama 3.3 70B, Llama 4 Maverick, Llama 4 Scout, Qwen3 235B, 32B, 30B, and more – optimized for seamless deployment on widely used frameworks, such as vLLM and SGLang. These models are quantized by AMD Quark, our open-source model optimization toolkit.
AI Performance Enablement#
Model performance is underpinned by the implementation of efficient kernels and the utilization of GPU compute units. To address both of these critical pieces, AITER supports ROCm 7.0 at launch. ROCm 7.0 also expands the use of the Stream-K algorithm on new GPUs, including the MI350 series.
Stream K reduces the need for lengthy GEMM tuning exercises, such as in PyTorch tunable ops, by efficiently load-balancing GEMM operations. In cases where the number of tiles is not evenly divisible amongst compute units, Stream K balances workloads across all compute units, achieving maximum GPU utilization. This all happens automatically, under the hood, leading to a considerable reduction in manual tuning required by the end user.
Finally, ROCm 7.0 expands the list of pre-optimized kernels in our open-source AITER library, including the addition of MXFP4 MoE kernels. These kernels, custom built by our engineers, can be easily dropped into users’ code bases and are automatically enabled in our latest training and inference docker containers. To see a list of these kernels, as well as learn more about AITER, check out these blog posts (1) (2).
Training#
To further AMD’s focus on delivering state-of-the-art pre and post training solutions, with ROCm 7.0, we’re introducing Primus.
Primus is the one-stop shop for model training on Instinct, offering end-to-end solutions for pre-training and fine-tuning, with reinforcement learning coming soon.
Primus combines the unique benefits of Instinct GPUs’ current training solutions into ONE optimized interface with multiple backends. This includes key operators, parallelism techniques, and kernels from various training dockers, now all consolidated and optimized within Primus.
Primus is currently in an early access state and will be incrementally improved with important new features such as reinforcement learning in future ROCm 7.x releases.
Looking ahead to these enhancements, we examine the hardware advancements that will drive Primus and Instinct GPUs’ cutting-edge capabilities.
Hardware Enablement: AMD Instinct MI350 Series GPUs#
ROCm 7.0 introduces the enablement of AMD’s Instinct™ MI350 series GPUs. These GPUs bring new floating-point data type capabilities—FP4, FP6, and FP8 (OCP float8 E4M3)—designed to accelerate AI inference workloads. These new data type capabilities address key customer challenges, providing substantial improvements in computational throughput, memory bandwidth utilization, and energy efficiency. We’ve enhanced FP16 and FP8 support and introduced new lower-precision formats, delivering not just a technical update but a significant step towards more efficient computation and memory usage. Read the documentation on Data Types and Precision Support for more information and start utilizing these powerful features in your AI research. Figure 2 shows an architectural diagram of the MI350 series GPUs, which feature eight Accelerator Complex Dies (XCDs), each integrating 32 AMD CDNA™ 4 Compute Units built on advanced N3P process technology. This configuration provides a total of 256 compute units, paired with 256 MB of AMD Infinity Cache™ to dramatically reduce memory latency and improve bandwidth efficiency. Together, these architectural advances enable the MI350X to deliver exceptional throughput for large-scale AI training and inference workloads, while maintaining high energy efficiency and scalability. Refer to the CDNA4 architecture whitepaper and the product page for more details. The following section outlines the key software enhancements designed to unlock the capabilities of the MI350 series GPU.
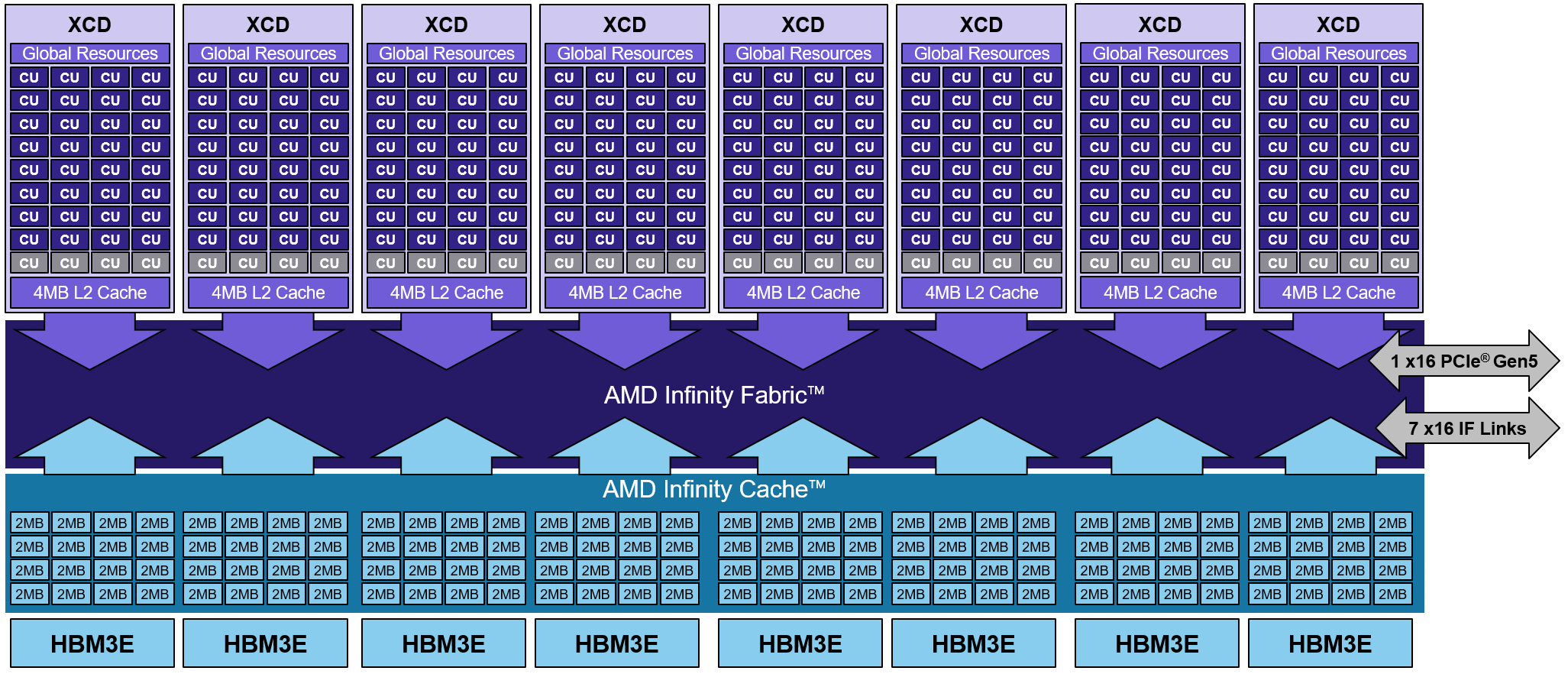
Figure 2. MI350 series GPU architecture#
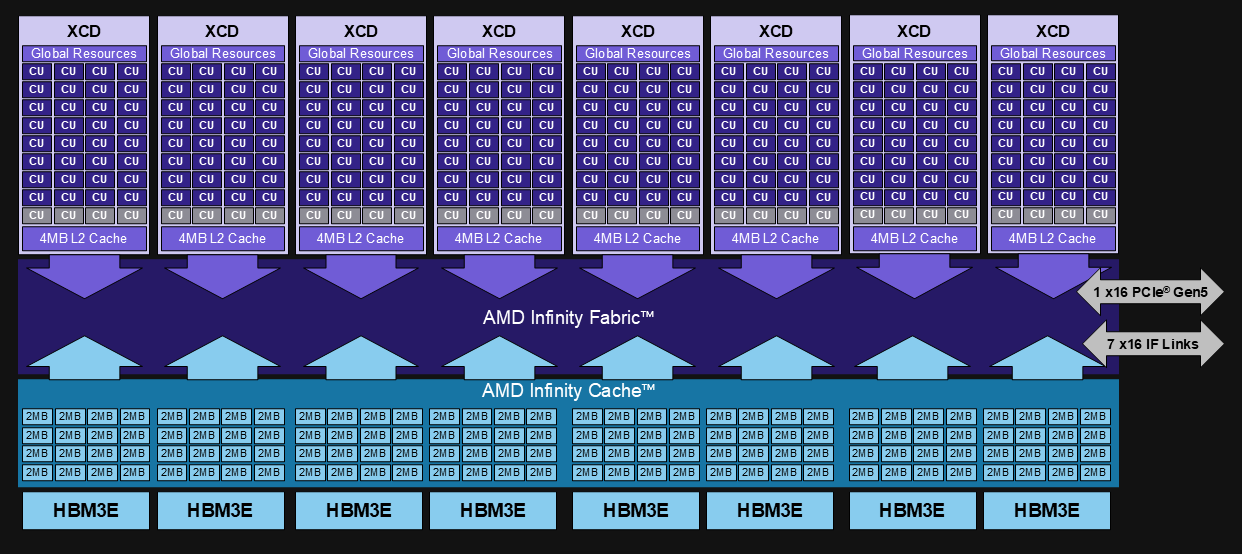
Figure 2. MI350 series GPU architecture#
The ROCm 7.0 SDK#
Targeted for our software developer community, we’ve made great strides in adding new features and performance improvements to our SDK. HIP C++ and runtime have improved compatibility with our competition. As the number of projects in the ROCm SDK grows, we are adopting a new classification system, as shown in Figure 3 below. Please see our release notes for additional details. This section details the improvements released in the ROCm 7.0 SDK, the foundation for our AI framework support. Incremental improvements in the SDK, such as optimizations in the math and compute libraries, may improve end-to-end AI performance.

Figure 3. The ROCm 7.0 SDK#

Figure 3. The ROCm 7.0 SDK#
Runtime & Compiler#
HIP now forwards exceptions to applications, adds CUDA-compatible launch APIs and zero-copy GPU-NIC transfer support, removes the runtime unbundler, improves SDMA engine reporting, and streamlines stream validation for greater stability and performance. Read more about the HIP API 7.0 changes in our release notes blog post.
LLVM is updated to version 20. Read more about the compiler changes in the release notes.
Math & Compute Libraries#
ROCm 7.0 introduces significant enhancements across its BLAS and sparse libraries, boosting performance, precision, and flexibility for GPU-accelerated linear algebra and AI workloads.
The hipBLASLt library now supports a wide range of data formats, including FP32, FP16, BF16, FP8, and BF8—alongside fused activation functions like Swish, SiLU, and GELU, enabling more efficient matrix multiplication on the MI300A APU. Memory and performance tuning improvements further optimize GEMM operations for diverse tensor shapes.
hipBLAS adds better workspace memory control and streamlines its API under HIPBLAS_V2, improving usability and reducing memory stalls.
rocBLAS benefits from broader hardware support, modernized build tools, and targeted optimizations for GEMM and GEMV routines, especially in large batch sizes and high-dimensional workloads.
hipSPARSE expands support for low-precision data types and introduces mixed precision across key routines, improving performance with minimal accuracy trade-offs.
hipSPARSELt enhances block-sparse operations with FP8/BF8 support and kernel tuning for MI300A, while integrating profiling tools like ROC-TX. rocSPARSE introduces new routines like SpGEAM and v2_SpMV, expands half-float precision, and improves runtime efficiency through smarter memory usage and build optimizations. Solver libraries rocSOLVER and hipSOLVER also evolve.
rocSOLVER adds hybrid CPU-GPU execution and support for SVD via Cuppen’s algorithm. Performance has been boosted for routines like
BDSQR,SYEV/HEEV,GEQR2, andGEQRF, while memory usage has been reduced for eigensolvers such asSTEDC,SYEVD/HEEVD, andSYGVD/HEGVD.hipSOLVER improves CUDA compatibility for sparse matrix workflows. Together, these updates make ROCm 7.0 a more powerful and developer-friendly platform for scientific computing, machine learning, and high-performance AI applications.
hipCUB updates enable GPU binary compression by default, reducing build sizes and improving multi-target build reliability. It also adds efficient single-pass scan operators and inclusive scans with custom initial values, aligning more closely with upstream CUB functionality and improving integration with rocPRIM.
rocThrust sees better modularity and testing, with upgraded benchmarking tools and compatibility improvements through CCCL/thrust 2.6.0 integration.
rocRAND strengthens reliability with expanded unit tests, refined error handling, and optimized tuning for MI300 GPUs, making it more robust for statistical simulations.
rocPRIM introduces new utilities and APIs for improved numerical stability and flexible data transformations, while optimizing multi-stream workloads and scan operations.
rocFFT enhances fast Fourier transform capabilities with new single-precision kernels and optimized plans for large 1D transforms, improving throughput and efficiency for high-performance computing tasks.
ROCm 7.0 introduces major upgrades to its AI and HPC acceleration stack through enhancements in Composable Kernel, MIOpen, and rocWMMA libraries.
Composable Kernel now supports a broader range of data types and delivers higher throughput and efficiency for large-scale model deployment.
MIOpen improves convolution performance by fusing multiple operations into single, optimized kernels, significantly reducing memory traffic and latency.
rocWMMA expands matrix-multiply-accumulate capabilities with support for interleaved layouts and mixed precision formats like BF8 and FP8. The new Fragment Scheduler API and static loop unrolling enhance control and reduce overhead, while unified fragment APIs and wave-level optimizations improve kernel occupancy and parallelism.
Together, these updates streamline development and boost performance for AI and scientific computing workloads on AMD hardware.
Communication Libraries#
With ROCm 7.0, RCCL, ROCm’s collective communication library, has been upgraded to deliver faster, more reliable multi-GPU and multi-node performance. Enhancements include zero-copy transfers that allow tensors to move directly between servers, fused NIC support that treats multiple network interfaces as a single high-bandwidth channel, and refinements to core collective algorithms such as ring, tree, and CollNet. Tree/PAT optimizations now provide greater numerical stability for large-scale reductions, while a new networking API improves packet ordering, skips unnecessary bookkeeping, and offloads small tasks like all-gather “fill” operations to reduce latency and jitter. These upgrades are complemented by improved resilience features, including automatic retries for failed socket and InfiniBand connections, expanded host-memory allocation paths, and richer profiler hooks for clearer traces and faster debugging. More documentation on RCCL can be found here.
Beyond communication efficiency, ROCm 7.0 also brings greater reliability and deployment flexibility. A dedicated RAS (Reliability, Availability, and Serviceability) thread and a new rcclras tool offer proactive health monitoring to detect issues before they interrupt workflows. FP8 (e5m2, e4m3) precision is now supported, enabling faster compute while maintaining accuracy. Networking is further hardened with multi-rail safety checks and CPU proxy offloading, reducing the risk of bottlenecks or connection failures. Integrated Open MPI in SLES15 base images simplifies cluster setup, accelerating out-of-box deployments. Together, these improvements ensure more consistent performance, fewer job interruptions, and smoother user experience when scaling training and inference workloads across AMD Instinct GPUs.
Computer Vision and Image Processing#
ROCm 7.0 delivers a comprehensive upgrade to our computer vision stack, enabling faster, more flexible, and production-ready vision workflows for AI and HPC developers. This release focuses on accelerating the entire image processing pipeline, enhancing data loading and decoding as well as expanding augmentation and transformation operations. Keep an eye out for upcoming additions to our Computer Vision libraries, including the consolidation of new and existing vision libraries into a targeted, easy-to-use toolkit.
rocAL: Data loading and decoding support in rocAL has been expanded to include hardware decoding support for both the video and image loaders, support for reading NumPy and webdataset file formats, and support for simultaneously loading multiple datasets in parallel from the same pipeline. Additionally, log1p augmentation functionality, as well as support for normalization and transpose operations are included in this update.
RPP: The ROCm Performance Primitives (RPP) suite is enhanced with support for bitwise logical operations, tensor concatenation augmentation, JPEG-compression-distortion augmentation, and log1p tensor augmentation. Further enhancements include optimized load/store operations for FP16, as well as expanding support for the F32 data-type to additional augmentation functions. Some API updates have been made to conform with industry standards to consolidate functionality for a more intuitive user experience.
Profiling & Debugging#
ROCm 7.0 expands profiling and debugging capabilities with upgrades across ROCProfV3, AQL Profiler, and the ROCprofiler-SDK. ROCProfV3 now supports decoded PC-sampling (including stochastic/hardware sampling on MI355X), per-counter reporting, SQL database export, and improved kernel tracing accuracy through swizzledA and LocalSplitU optimizations. The AQL Profiler has been streamlined by adopting a shared SDK-based SQTT decoder, moving to sanitized hardware headers, decoupling from ROCr, updating device ID handling, and strengthening its test suite.
The ROCprofiler-SDK integrated the SQTT decoder, adds APIs for dynamic derived counters, Hyper-V support, API-buffer tracing with argument context, and high-throughput channels (NPS2 + DPX). Tools now generate database-style outputs, merge traces, and export Perfetto-compatible traces, while new features like agent-ID selection and ASCII-based memory charts improve usability. Debugging advances include ROCgdb support for host traps, LLVM-specific DWARF encodings, and automated test configuration based on detected GPUs, delivering a more robust, flexible toolkit for performance analysis and troubleshooting.
AMD Datacenter Infrastructure and Enterprise AI Tools#
This section highlights support added for datacenter infrastructure such as Operating Systems, Virtualization, Containers and Orchestration—alongside tools and capabilities designed to accelerate enterprise AI adoption. Read about these in the Instinct documentation.
Enterprise AI: Open, Scalable, and Ready for Deployment#
As AI adoption accelerates across industries, enterprises need infrastructure that is open, scalable, and easy to manage. With the release of ROCm 7.0, AMD introduces a new suite of tools designed for enterprise customers to deploy and scale AI workloads with confidence.
AMD Resource Manager: Smarter Orchestration at Scale
Intelligent Resource Scheduling: Dynamically allocate resources based on policies and priorities, minimizing idle GPUs and maximizing throughput.
User & Project Quota Management: Ensure fair and efficient compute distribution across teams with smart quota enforcement and adaptive scaling.
Telemetry & Analytics: Gain deep visibility into compute usage and performance, enabling continuous optimization through real-world feedback.
Managing AI infrastructure across clusters can be complex. AMD Resource Manager (Figure 4) provides a dashboard with intelligent orchestration and workload optimization across Kubernetes, Slurm, and other enterprise environments.
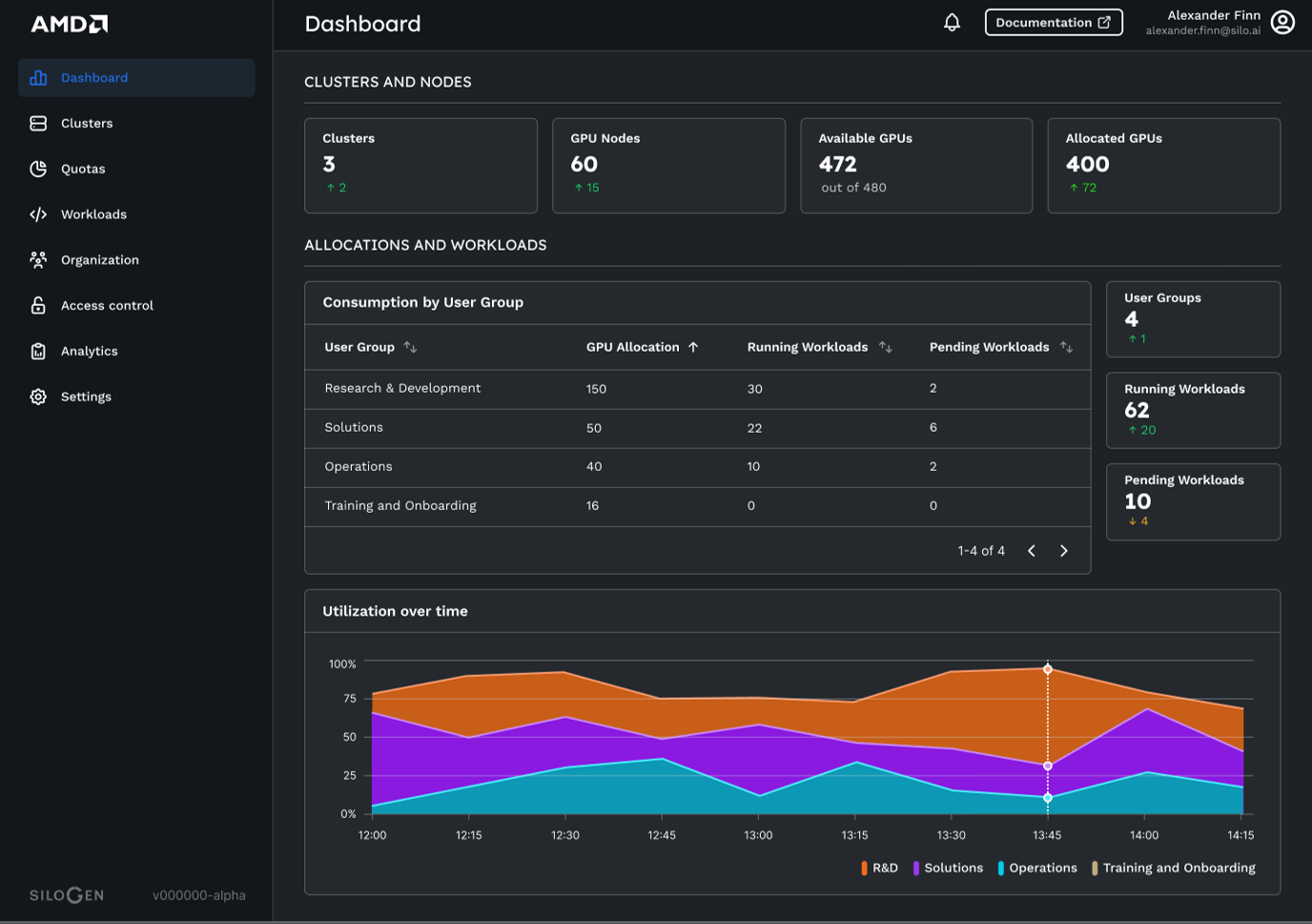
Figure 4. Manage your resource scheduling, project quota, telemetry and analysis with AMD Resource Manager.#
AMD AI Workbench: Flexible AI Development & Deployment
Training & Fine-Tuning Pipelines: Leverage pre-optimized pipelines for popular foundation models, ready to run on AMD hardware.
Developer Workspaces: Choose from notebooks, IDEs, or SSH-based environments tailored to your workflow.
Community Developer Tools: Access a rich ecosystem of tools for tracking experiments, benchmarking, and profiling.
AMD AI Workbench (Figure 5) provides a flexible interface for deploying, adapting, and scaling AI models, with built-in support for inference, fine-tuning, and integration into enterprise workflows.
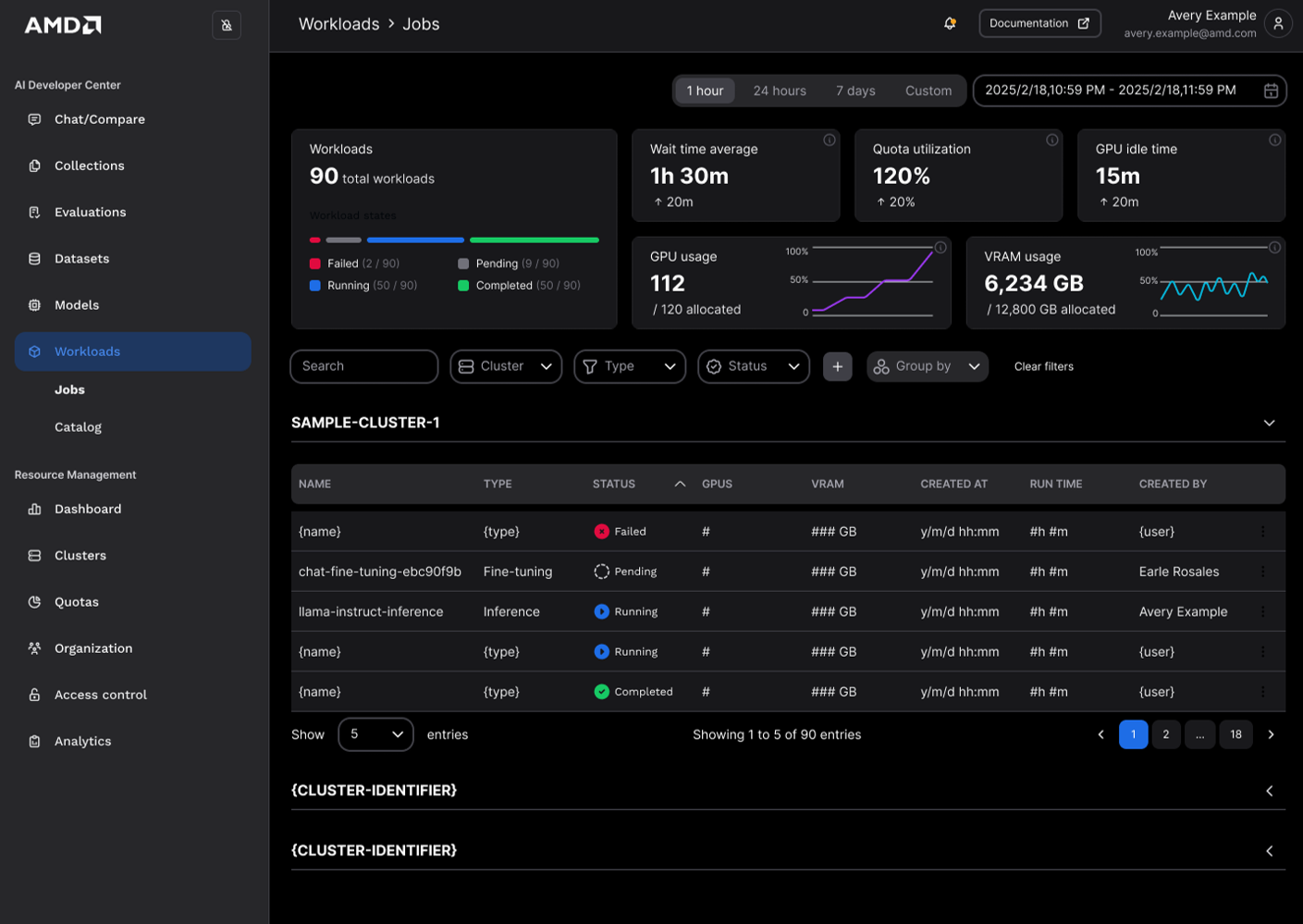
Figure 5. AMD AI Workbench is a unified platform for training and fine-tuning pipelines, developer workspaces, and community workspaces.#
You can learn more about how AMD enterprise AI tools support scalable deployment and management in diverse production environments by accessing and exploring our Enterprise AI portal.
AMD GPU Drivers & Operating System Support#
Installation docs and release notes are now split between the AMD GPU Driver and ROCm SDK, letting users choose combinations of the two during installation. This allows users to update the AMD GPU Drivers and the ROCm toolkit independently.
AMD GPU driver 30.10.0 adds support for the MI350X and MI355X.
enables bare-metal SPX+NPS1 and DPX + NPS2 partitioning modes on the MI350X and MI355X.
Partitioning modes allow dividing of Instinct GPUs into up to multiple compute and memory partitions, smaller “virtual GPUs” for improved GPU utilization and performance when running workloads that do not need the entire GPU.
Instinct driver support has expanded to include the following operating systems:
Rocky Linux 9
latest minor versions of Ubuntu 22.04.5, Ubuntu 24.04.3
For the new MI350X and MI355X, it enables Ubuntu 24.04.3, RHEL 9.4, RHEL 9.6, and Oracle Linux 9.
AMD GPU Virtualization Support & Drivers#
AMD GPU SR-IOV Virtualization driver 8.4 adds the following:
SRIOV SPX / NPS1 (1 compute / 1 memory partition per GPU) on MI350X and MI355X
VMWare ESXi 8U3 now supports Passthrough virtualization on MI300X and MI325X
AMD GPU Operator#
GPU Operator 1.3.1, released in August 26, added support to OpenShift v4.19 and for GPU partitioning on MI300 series GPUs. Refer to the release notes for additional details.
The GPU operator 1.4.0 release, available soon, will add the following features:
Full ROCm 7.0 Support: Seamless compatibility with the latest runtime and software stack
Support for Instinct MI350 Series GPUs: Expanding hardware compatibility
AGFHC Integration: Built-in AMD GPU Field Health Check for runtime diagnostics and monitoring
Summary#
As we’ve shown in this blog, ROCm 7.0 is far more than a version bump—it’s a major leap forward for AI on AMD GPUs and across the broader AI framework ecosystem. With hardware enablement for the Instinct™ MI350X and MI355X at its foundation, this release brings new FP4/FP6/FP8 precision formats, AITER’s pre-optimized operators, and production-ready models from AMD Quark. Combined with day-0 support for frameworks like PyTorch, TensorFlow, and JAX, ROCm 7.0 ensures developers can work seamlessly with the tools they already rely on while gaining faster training, lower-latency inference, and higher efficiency at every scale.
We believe that ROCm 7.0 empowers our community with a clearer, faster path from idea to production. With native integrations for vLLM and SGLang, and enhanced multi-GPU scaling through RCCL, developers can train and deploy larger models with less complexity. HIP 7.0 improves portability across platforms, while enterprise-ready tools streamline deployment and management—allowing teams to spend less time wrestling with infrastructure and more time building solutions.
And this is only the start. We are planning to refresh the UX of our profiler tools to make performance insights easier to capture and act on. We are also planning to release the open-source AMD Infinity Storage, a GPU-optimized solution to reduce file I/O bottlenecks and keep data pipelines flowing, and much more. Looking ahead, we remain strongly committed to advancing ROCm as an open, enterprise-grade platform designed to power the next generation of AI innovation.