Recent Posts - Page 18#

GEMM Tuning within hipBLASLt - Part 1
We introduce a hipBLASLt tuning tool that lets developers optimize GEMM problem sizes and integrate them into the library.

Step-3 Deployment Simplified: A Day 0 Developer’s Guide on AMD Instinct™ GPUs
Learn how to deploy Step-3, a 321B-parameter VLM with MFA & AFD, on AMD Instinct™ GPUs to cut decoding costs and boost long-context reasoning

Unleashing AMD Instinct™ MI300X GPUs for LLM Serving: Disaggregating Prefill & Decode with SGLang
Learn how prefill–decode disaggregation improves LLM inference by reducing latency, enhancing throughput, and optimizing resource usage.

QuickReduce: Up to 3x Faster All-reduce for vLLM and SGLang
Quick Reduce speeds up LLM inference on AMD Instinct™ MI300X GPUs with inline-compressed all-reduce, cutting comms overhead by up to 3×

AITER-Enabled MLA Layer Inference on AMD Instinct MI300X GPUs
AITER boosts DeepSeek-V3’s MLA on AMD MI300X GPUs with low-rank projections, shared KV paths & matrix absorption for 2× faster inference.

Primus: A Lightweight, Unified Training Framework for Large Models on AMD GPUs
Primus streamlines LLM training on AMD GPUs with unified configs, multi-backend support, preflight validation, and structured logging.

Introducing AMD EVLM: Efficient Vision-Language Models with Parameter-Space Visual Conditioning
A novel approach that replaces visual tokens with perception-conditioned weights, reducing compute while maintaining strong vision-language performance.

DGL in the Real World: Running GNNs on Real Use Cases
We walk through four advanced GNN workloads from heterogeneous e-commerce graphs to neuroscience applications that we successfully ran using our DGL implementation.
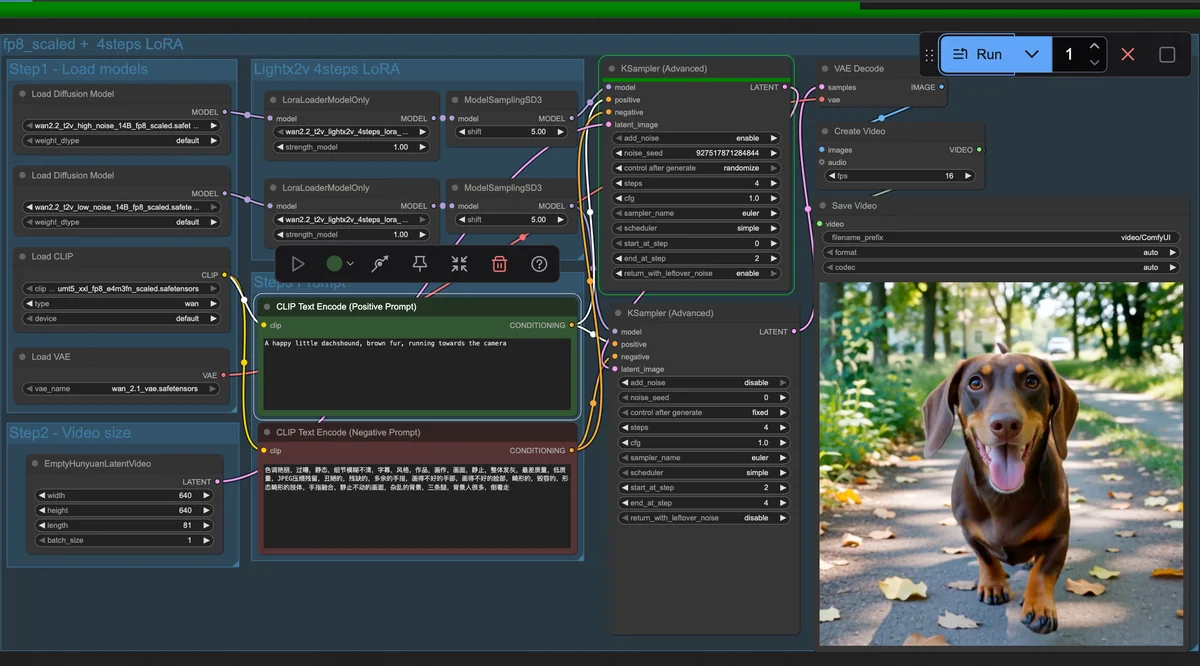
Running ComfyUI on AMD Instinct
This blog shows how to deploy ComfyUI on AMD Instinct GPUs. The blog explains what ComfyUI is and how it works.

Accelerating FastVideo on AMD GPUs with TeaCache
Enabling ROCm support for FastVideo inference using TeaCache on AMD Instinct GPUs, accelerating video generation with optimized backends
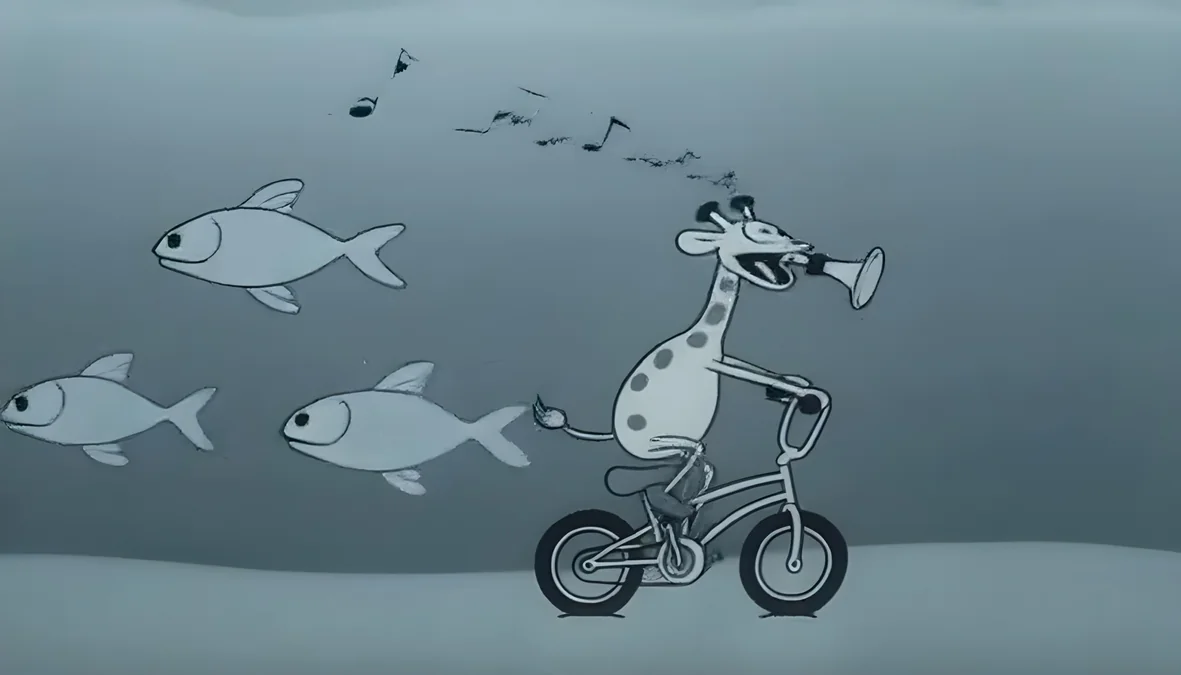
Wan2.2 Fine-Tuning: Tailoring an Advanced Video Generation Model on a Single GPU
Fine-tune Wan2.2 for video generation on a single AMD Instinct MI300X GPU with ROCm and DiffSynth.

All-in-One Video Editing with VACE on AMD Instinct GPUs
This blog showcases AMD hardware powering cutting-edge text-driven video editing models through an all-in-one solution.