AI - Applications & Models - Page 2#

A Practical Guide to Running LLMs on AMD Radeon™ GPUs
This guide describes how to run LLMs on AMD Radeon™ GPUs using a range of partner frameworks, tools, and runtimes, with step-by-step setup instructions and performance optimization tips.

Comparative Analysis of Scale-Out RoCE Network Traffic Patterns and Loads in Training Large Language Models
Compares RoCE network traffic patterns and loads across GPT-4, Llama 3, DeepSeek-V2, and Grok 4.0 LLM training to guide AI infrastructure design.

Utilizing AMD Schola and UnrealRoboticsLab with AMD ROCm™ Software to Train a Robotic Arm
Learn how to combine MuJoCo physics, Unreal Engine, and Schola to train a 6-DOF robot arm with reinforcement learning on AMD hardware.

Technical Dive into AMD's MLPerf Training v6.0 Submission
In this blog, we share the technical details of how we accomplish the results in our MLPerf Training v6.0 submission.

Reproducing AMD MLPerf Training v6.0 Submission Result
Learn how to reproduce AMD's MLPerf Training v6.0 submission result.

Low Kruskal-Rank Adaptation
Learn how Kruskal rank can enhance LoRA by replacing the conventional matrix-rank formulation for more efficient training.

Productionizing TurboQuant on AMD GPUs for KV-Cache-Bound LLM Inference
Productionized TurboQuant 4-bit KV-cache quantization on AMD GPUs via vLLM, with custom kernels and accuracy analysis on agentic workloads.
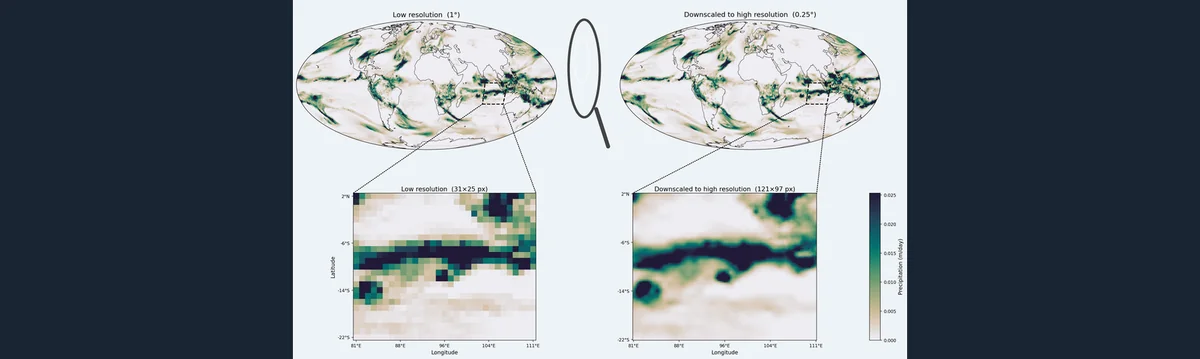
ORBIT-2 based Weather and Climate Downscaling and Downscaled Global Forecasts on AMD Instinct
A showcase for how to run GenCast’s weather prediction with ORBIT-2’s high-resolution downscaling on AMD Instinct hardware.

Out-of-the-Box ROLL Support on AMD GPUs: Accelerating Reinforcement Learning at Scale
Learn how to run Alibaba's ROLL RL framework out-of-the-box on AMD Instinct™ GPUs with ROCm

Enabling Speculative Speculative Decoding on MI300X
This is an introduction of speculative speculative decoding method. We enable this method on the AMD Instinct MI300x GPUs and report the results.

AI Inference on AMD Ryzen™ AI Max Processor
Hands-on: run Qwen3.5 9B–122B on Ryzen™ AI Max+ with 128GB UMA and Ollama, with generation benchmarks and a clear UMA setup path on Ubuntu/ROCm.

Diffusion-based Atmospheric Downscaling on AMD Instinct GPUs
Read this blog post to learn about and understand the theory of downscaling models. Also learn how to run a particular model, CorrDiff, on AMD GPUs.