AI - Applications & Models#

Local Image and Video Generation on AMD Ryzen™ AI Max+ Processor (Windows)
Run ComfyUI natively on Windows on AMD Ryzen AI Max+ with ROCm 7.2.1—SDXL, Flux, and video workflows on the Radeon 8060S, no WSL.

QuickReduce INT3 Quantization and Benchmarking on MI355
Learn how QuickReduce uses INT3 quantization to accelerate all-reduce communication and evaluate its performance and accuracy on AMD Instinct MI355 GPUs.

Triton-Based Optimization of Video Sparse Attention on ROCm
Optimize video sparse attention on ROCm with GEAK and linear global context for faster, more stable video generation on AMD GPUs.

Fast Image Generation and Editing with SGLang Diffusion on AMD GPUs
Serve and benchmark diffusion models for image generation and editing on AMD Instinct GPUs using SGLang Diffusion on ROCm.

AMD Instinct™ Network Traffic, Congestion Trends, and Harmonics in Scale-Out Networks for AI Training Clusters
Explore how synchronized GPU collectives create harmonic congestion in AI clusters and the strategies to diagnose and mitigate it.

Towards Feature Complete Triton Support in JAX-Triton
Learn what new features were added to JAX-Triton and how that could help you write or reuse more efficient and readable GPU kernels in JAX.

Efficient Hyperparameter Optimization for Autonomous Driving Models with AMD Instinct GPU Partitioning
Accelerate HPO for autonomous driving models using AMD MI300X GPU partitioning for higher throughput, efficiency, and parallelism.

Accelerating Diffusers and xDiT Image Generation with MXFP4 using AMD Quark on AMD Instinct™ MI350 GPUs
Accelerate Diffusers and xDiT FLUX.1-dev image generation on AMD Instinct MI350 GPUs using AMD Quark MXFP4 quantization.
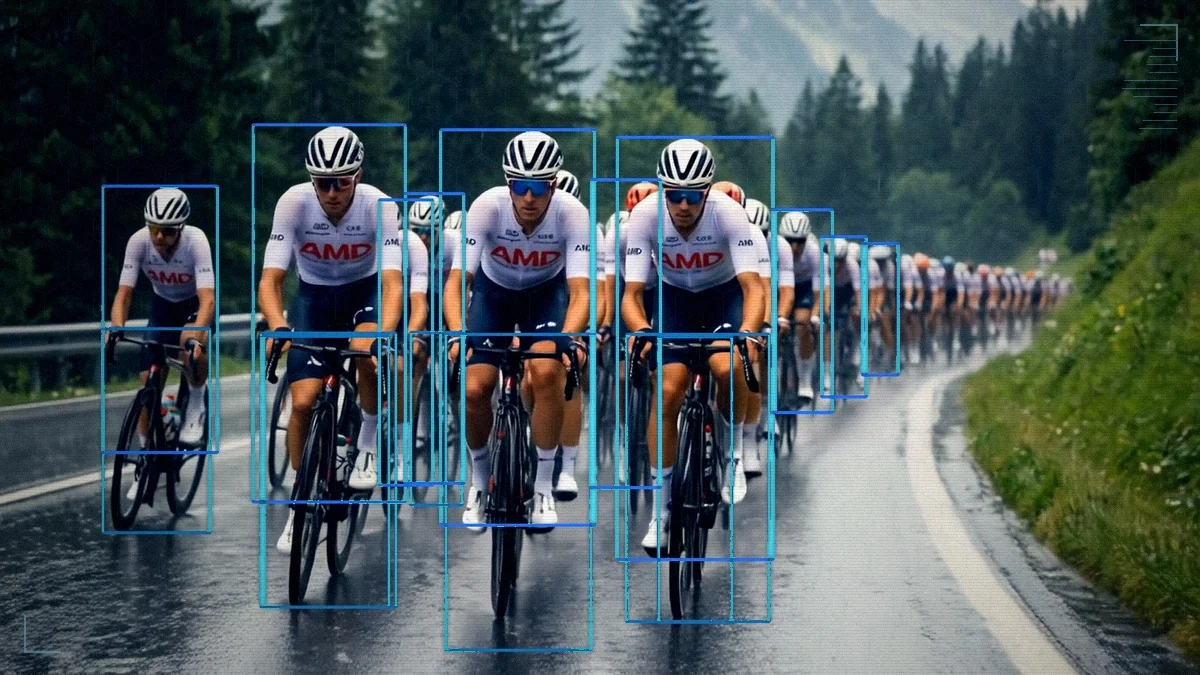
Building a GPU-Resident YOLO26 Object Detection Pipeline on the AMD Radeon™ AI PRO R9700 GPU
Build a GPU-resident object detection pipeline on AMD GPUs with rocDecode, DLPack, and MIGraphX. Frames stay in VRAM end to end.

Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.

MXFP6 and MXFP4 Mixed Precision for Accelerating Dense LLMs on AMD Instinct MI355X
W_MXFP4_A_MXFP6 quantization on AMD Instinct MI355X improves LLM throughput and latency while recovering accuracy versus MXFP4.
Faster Kimi-K2.5-W4A8 Decoding with EAGLE3 on AMD Instinct™ MI325X
Add EAGLE3 speculative decoding and three MoE/FMHA kernel-tuning patches to Kimi-K2.5-W4A8 inference on AMD Instinct™ MI325X with SGLang, AITER, and FlyDSL.