Introducing Instella: New State-of-the-art Fully Open 3B Language Models#

AMD is excited to announce Instella, a family of fully open state-of-the-art 3-billion-parameter language models (LMs) trained from scratch on AMD Instinct™ MI300X GPUs. Instella models outperform existing fully open models of similar sizes and achieve competitive performance compared to state-of-the-art open-weight models such as Llama-3.2-3B, Gemma-2-2B, and Qwen-2.5-3B, including their instruction-tuned counterparts.
Our journey with Instella builds upon the foundation laid by our previous 1-billion-parameter LMs, AMD OLMo which helped showcase the feasibility of training LMs end-to-end on AMD GPUs. With Instella, we have scaled our efforts by transitioning from a 1-billion-parameter model trained on 64 AMD Instinct MI250 GPUs using 1.3T tokens to a 3-billion-parameter model trained on 128 Instinct MI300X GPUs using 4.15T tokens. While we compared our previous model with similarly sized fully open models only, Instella not only surpasses existing fully open models but also achieves overall competitive performance as compared to state-of-the-art open-weight models (Figure 1 [1].), marking a significant step in bridging this gap.
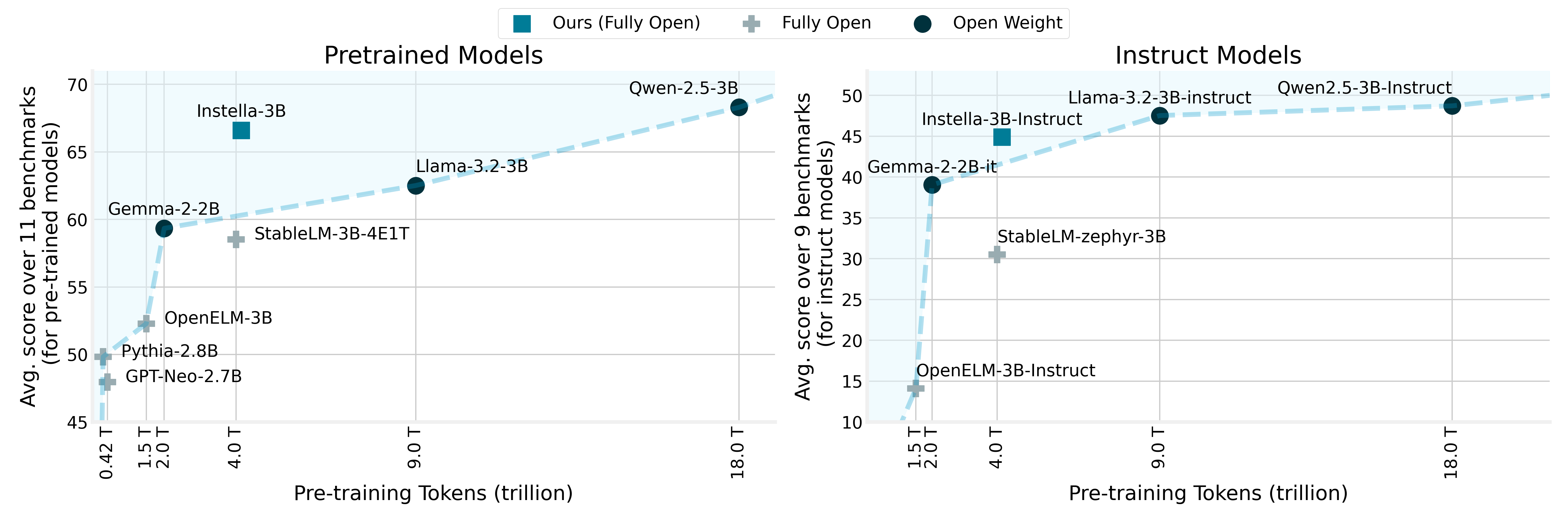
Figure 1: Comparing Instella Performance: Pareto frontier of pre-training tokens vs average performance for pre-trained and instruction-tuned models.#
By training Instella from scratch on Instinct MI300X GPUs, we highlight our hardware’s capability and scalability in handling demanding AI training workloads, offering a viable alternative in the AI hardware landscape. In line with AMD’s commitment to open source, we are releasing all artifacts related to Instella models here, including the model weights, detailed training configurations, datasets, and code, enabling the AI community to collaborate, replicate, and innovate, thereby accelerating progress.
This blog will introduce you to our new family of Instella LMs. You will find out how to access these new models, learn, in details, how we trained them, and see how AMD’s new Instella LMs benchmark with other models. Follow the Additional Resources section to get started with using Instella models.
Takeaways#
Announcing Instella, a series of 3 billion parameter language models developed by AMD, trained from scratch on 128 Instinct MI300X GPUs.
Instella models significantly outperform existing fully open LMs (Figure 1) of comparable size, as well as bridge the gap between fully open and open weight models by achieving competitive performance compared state-of-the-art open weight models and their instruction-tuned counterparts.
Fully open and accessible: Fully open-source release of model weights, training hyperparameters, datasets, and code, fostering innovation and collaboration within the AI community.
Supported by the AMD ROCm software stack, Instella employs efficient training techniques such as FlashAttention-2, Torch Compile, and Fully Sharded Data Parallelism (FSDP) with hybrid sharding to scale model training over a large cluster.
Instella Models#
In this release, we introduce the following Instella models (Table 2):
Model |
Stage |
Training Data (Tokens) |
Description |
|---|---|---|---|
Pre-training (Stage 1) |
4.065 Trillion |
First stage pre-training to develop proficiency in natural language. |
|
Pre-training (Stage 2) |
57.575 Billion |
Second stage pre-training to further enhance problem solving capabilities. |
|
SFT |
8.902 Billion (x3 epochs) |
Supervised Fine-tuning (SFT) to enable instruction-following capabilities. |
|
DPO |
760 Million |
Alignment to human preferences and strengthen chat capabilities with direct preference optimization (DPO). |
|
Total: |
4.15 Trillion |
The Instella models are text-only, autoregressive transformer-based LMs having 3 billion parameters. Architecture-wise, Instella is packed with 36 decoder layers, each having 32 attention heads. These models support a sequence length of up to 4,096 tokens and have a vocabulary size of ~50,000 tokens using the OLMo tokenizer[2]. During both pre-training and fine-tuning, we utilized FlashAttention-2[3], Torch Compile, and bfloat16 mixed-precision training to reduce memory usage, leading to computational speedups and optimal resource utilization. To balance inter-node memory efficiency and intra-node communication overhead within our cluster, we employed fully sharded data parallelism (FSDP) with hybrid sharding, with model parameters, gradients, and optimizer states sharded within a node and replicated across the nodes.
Our training pipeline is based on the open-sourced OLMo codebase, adapted, and optimized for our hardware and model architecture. For pre-training we used a total of 128 Instinct MI300X GPUs distributed across 16 nodes with each node having 8x Instinct MI300X GPUs. We evaluated our models and baselines using standard tasks from OLMES, FastChat MT-Bench, and Alpaca. For more details about the architecture, training hyperparameters and evaluations, please refer to our huggingface model card and our Github repository.
Training Pipeline#
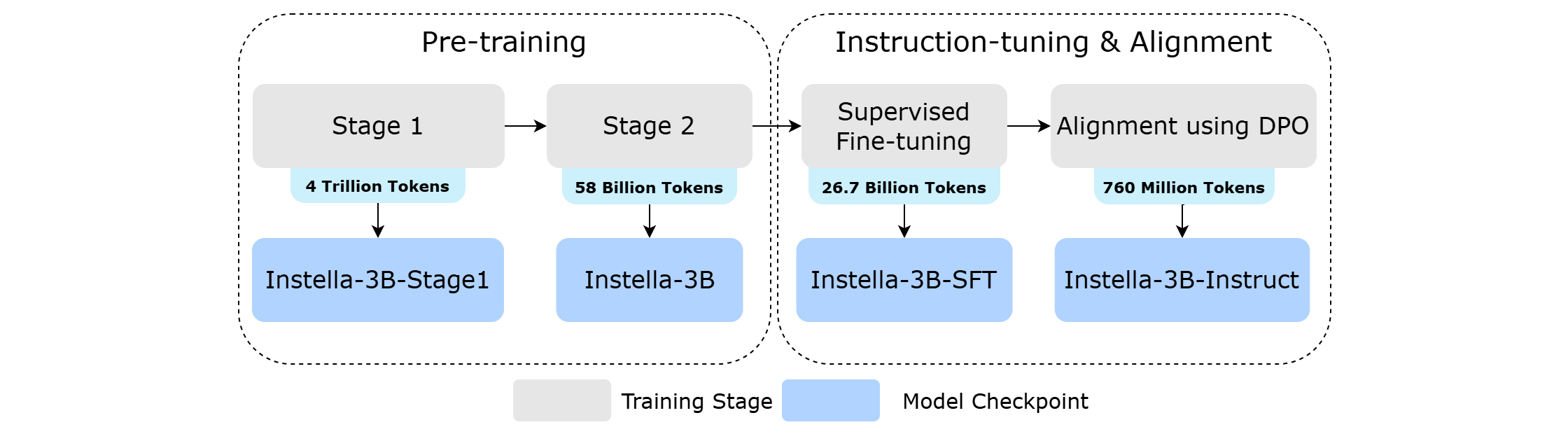
Figure 2: Instella model training pipeline.#
The training of the Instella models comprised of four stages (Figure 2), where each stage incrementally enhanced the model’s capabilities from fundamental natural language understanding to instruction following and alignment towards human preferences. In this section we will briefly present Instella’s two pre-training stages and two instruction tuning & alignment stages, and their benchmark results.
Two stage pre-training#
In the first pre-training stage, we trained the model from scratch on 4.065 trillion tokens sourced from OLMoE-mix-0924[4], which is a diverse mix of two high-quality datasets DCLM-baseline[5] and Dolma 1.7[6] covering domains like coding, academics, mathematics, and general world knowledge from web crawl. This extensive first stage pre-training established a foundational understanding of general language in our Instella model.
For our final pre-trained checkpoint, Instella-3B, we conducted a second stage pre-training on top of the first-stage Instella-3B-Stage1 model to further enhance its capabilities specifically in MMLU, BBH, and GSM8k. To accomplish this, we further trained the model on an additional 57.575 billion tokens sourced from high-quality and diverse datasets, specifically from Dolmino-Mix-1124[2], SmolLM-Corpus (python-edu)[7], the Deepmind Mathematics[8], and conversational datasets including Tülu-3-SFT-Mixture[9], OpenHermes-2.5[10], WebInstructSub[11], Code-Feedback[12], and Ultrachat 200k[13].
In addition to these publicly available datasets, 28.5 million tokens out of our second stage pre-training data-mix were derived from our in-house synthetic dataset focusing on mathematical problems. This synthetic dataset was generated using the training set of GSM8k dataset, where we first used Qwen2.5-72B-Instruct to 1) Abstract numerical values as function parameters and generate a Python program to solve the math question, 2) Identify and replace numerical values in the existing question with alternative values that are still answerable with the same python program solution as the original question. Next, by assigning different new values to these Python parameters and using the abstract solution program to compute the corresponding answers, we expanded our synthetic dataset with new and reliable question-answer pairs[14]. The conversational datasets in this second stage pre-training data-mix were reformatted by concatenating question-answer pairs to be used for pre-training. We trained the model on this data-mix three times with different random seeds and combined the model weights to obtain the final pre-trained model, Instella-3B.
| Models | Size | Training Tokens | Avg | ARC Challenge | ARC Easy | BoolQ | Hellaswag | PiQA | SciQ | Winnograde | OpenBookQA | MMLU | BBH (3-shot) | GSM8k (8-shot) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Weight Models | ||||||||||||||
| Gemma-2-2B | 2.61B | ~2T | 59.34 | 39.46 | 59.30 | 74.50 | 70.50 | 76.40 | 96.60 | 69.80 | 44.80 | 53.28 | 40.75 | 27.37 |
| Llama-3.2-3B | 3.21B | ~9T | 62.51 | 47.16 | 64.91 | 74.80 | 73.10 | 75.90 | 95.30 | 70.30 | 51.20 | 57.81 | 47.00 | 30.10 |
| Qwen2.5-3B | 3.09B | ~18T | 68.30 | 51.51 | 67.19 | 79.10 | 72.10 | 77.40 | 95.50 | 69.30 | 51.40 | 67.22 | 56.69 | 63.84 |
| Fully Open Models | ||||||||||||||
| Pythia-2.8b | 2.91B | 300B | 49.83 | 40.47 | 60.70 | 64.80 | 60.10 | 72.50 | 89.70 | 60.80 | 42.60 | 26.09 | 27.69 | 2.73 |
| GPTNeo-2.7B | 2.72B | ~420B | 47.96 | 38.46 | 54.56 | 62.70 | 55.20 | 70.80 | 88.00 | 58.30 | 40.80 | 27.83 | 27.25 | 3.71 |
| OpenELM-3B | 3.04B | ~1.5T | 52.28 | 37.46 | 58.42 | 68.60 | 71.70 | 75.60 | 92.50 | 65.40 | 46.40 | 26.69 | 29.40 | 2.96 |
| StableLM-3B-4E1T | 2.8B | ~4T | 58.51 | 44.82 | 67.02 | 75.40 | 74.20 | 78.40 | 93.40 | 68.40 | 48.60 | 45.19 | 37.33 | 10.84 |
| Instella-3B-Stage1 | 3.11B | ~4T | 61.33 | 53.85 | 73.16 | 78.70 | 74.20 | 77.50 | 94.90 | 71.20 | 51.40 | 54.69 | 34.30 | 10.77 |
| Instella-3B | 3.11B | ~4T+60B | 66.59 | 52.84 | 70.53 | 76.50 | 75.00 | 77.80 | 96.40 | 73.10 | 52.40 | 58.31 | 39.74 | 59.82 |
Pre-training Results#
Both Instella-3B-Stage1 & Instella-3B models outperform all the other fully open models over all the benchmarks individually (except PIQA) (Table 2). Our final pre-trained checkpoint Instella-3B outperforms the existing top performant fully open pre-trained models by a lead of ⬆️8.08% on average, with significant improvements in
ARC Challenge [+8.02%], ARC Easy [+3.51%], Winnograde [+4.7%], OpenBookQA [+3.88%], MMLU [+13.12%] and ️GSM8K [+48.98%].Second stage pre-training elevated the overall average performance relative to stage-1 by ⬆️5.26%, substantially narrowing the performance gap between Instella-3B model vs the closed-source models, and outperforming Llama-3.2-3B by ⬆️4.08% on average (
+5.69% [ARC Challenge], +5.61% [ARC Easy], and +29.72% [GSM8k]), Gemma-2-2B by ⬆️7.25% on average (+13.38% [ARC Challenge], +11.23% [ARC Easy], +4.5% [Hellaswag], +7.6% [OpenBookQA], +5.03% [MMLU], and +32.45% [GSM8k]), and is competitive with Qwen-2.5-3B on the majority of the benchmarks.The multi-stage pre-training with diverse and high-quality data mix significantly enhanced Instella-3B’s capabilities, establishing it as a competitive and open alternative in the landscape of comparable size language models.
Instruction Tuning & Alignment#
The supervised fine-tuning stage was done to enhance the Instella-3B base pre-trained model’s ability to follow instructions and respond to user queries. Instella-3B-SFT was supervised fine-tuned using Instella-3B as the base model and training with 8.9 billion tokens of high-quality instruction-response pairs data for three epochs. The primary objective was to improve the base model’s performance in interactive settings, making it better suited for tasks requiring understanding and executing user commands. During this phase, we utilized curated datasets that spanned across a broad spectrum of tasks and domains, ensuring that the model could generalize across various instruction types. This data-mix was selectively soured from SmolTalk (1.04M samples)[15], OpenMathinstruct-2 (1M subset)[16], Tulu 3 Instruction Following (30k samples)[9], MMLU auxiliary train set[17], and o1-journey[18].
In the final training stage, we focused on aligning the Instella-3B-SFT model with human preferences to ensure that its outputs are helpful, accurate, and safe. Using Instella-3B-SFT as the base model, Instella-3B-Instruct was trained with Direct Preference Optimization (DPO)[19] on 0.76 billion tokens sourced from OLMo 2 1124 7B Preference Mix[2]. This alignment process was essential for tailoring the model’s responses to be more in line with human values and expectations, thereby enhancing the quality and reliability of its outputs.
| Models | Size | Training Tokens | Avg | MMLU | TruthfulQA | BBH | GPQA | GSM8K | Minerva MATH | IFEval | AlpacaEval 2 | MT-Bench |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Open Weight Models | ||||||||||||
| Gemma-2-2B-Instruct | 2.61B | ~2T | 39.04 | 58.35 | 55.76 | 42.96 | 25.22 | 53.45 | 22.48 | 55.64 | 29.41 | 8.07 |
| Llama-3.2-3B-Instruct | 3.21B | ~9T | 47.53 | 61.50 | 50.23 | 61.50 | 29.69 | 77.03 | 46.00 | 75.42 | 19.31 | 7.13 |
| Qwen2.5-3B-Instruct | 3.09B | ~18T | 48.72 | 66.90 | 57.16 | 57.29 | 28.13 | 75.97 | 60.42 | 62.48 | 22.12 | 8.00 |
| Fully Open Models | ||||||||||||
| StableLM-zephyr-3B | 2.8B | 4T | 30.50 | 45.10 | 47.90 | 39.32 | 25.67 | 58.38 | 10.38 | 34.20 | 7.51 | 6.04 |
| OpenELM-3B-Instruct | 3.04B | ~1.5T | 14.11 | 27.36 | 38.08 | 24.24 | 18.08 | 1.59 | 0.38 | 16.08 | 0.21 | 1.00 |
| Instella-3B-SFT | 3.11B | ~4T | 42.05 | 58.76 | 52.49 | 46.00 | 28.13 | 71.72 | 40.50 | 66.17 | 7.58 | 7.07 |
| Instella-3B-Instruct | 3.11B | ~4T | 44.87 | 58.90 | 55.47 | 46.75 | 30.13 | 73.92 | 42.46 | 71.35 | 17.59 | 7.23 |
Instruction Tuning Results#
Instella-3B-Instruct model consistently outperforms other fully open models across all evaluated benchmarks with a significant average score lead of ⬆️ 14.37% w.r.t the next top performing fully open instruction-tuned models (Table 3). With substantial margins across all the chat benchmarks (
+13% [MMLU], 7.57% [TruthfulQA], 7.43% [BBH], +4.46% [GPQA], +37.15 [IFEval], 10.08% [Alpaca 2], and 1.2% [MT-Bench]).Instella-3B-Instruct narrows the performance gap with leading open-weight models. Instella-3B-Instruct performs on par with or slightly surpasses existing state-of-the-art open weight instruction-tuned models such as Llama-3.2-3B-Instruct (
+5.24% [TruthfulQA], 0.45% [GPQA], and +0.1% [MT-Bench]), and Qwen2.5-3B-Instruct (+2.01% [GPQA] and +8.87% [IFEval]), while significantly outperforming Gemma-2-2B-Instruct with an average score lead of ⬆️5.83% (+0.55% [MMLU], +3.79 [BBH], +4.91 [GPQA], +20.47 [GSM8k], +19.98 [Minerva MATH], and +15.17% [IFEval]).Overall, Instella-3B-Instruct excels in instruction following tasks and multi-turn QA tasks like TruthfulQA, GPQA, IFEval and MT-Bench, while being highly competitive compared to existing state-of-the-art open weight models on other knowledge recall and math benchmarks, while being trained on significantly fewer training tokens.
Summary#
The release of the Instella family of models represents a significant stride in advancing open-source AI and demonstrating the capabilities of AMD hardware in language model training. The 3 billion parameter models from Instella family significantly outperform present fully open comparable size models in key benchmarks while also being competitive to comparable open-weight models, which we attribute to the high-quality data-mix selection, multi-stage training pipeline, and the use of high-performance Instinct MI300X GPUs for training.
By fully open sourcing the Instella models, including weights, training configurations, datasets, and code, we aim to foster innovation and collaboration within the AI community. We believe that transparency, reproducibility and accessibility are key drivers of progress in AI research and development. We invite developers, researchers, and AI enthusiasts to explore Instella, contribute to its ongoing improvement, and join us in pushing the boundaries of what is possible with language models.
We will continue enhancing the models across multiple dimensions, including context length, reasoning ability, and multimodal capabilities. Additionally, we will scale up both the model and dataset while exploring diverse architectural approaches. Keep your eyes peeled for more exciting blogs on the Instella LMs family, its features and capabilities!
Additional Resources#
Hugging face Model Cards#
Pre-trained models:
Instella-3B-Stage1: amd/Instella-3B-Stage1, First stage pre-training checkpoint.
Instella-3B: amd/Instella-3B, Final pre-training checkpoint.
Instruction-tuned models:
Instella-3B-SFT: amd/Instella-3B-SFT, Supervised fine-tuned checkpoint.
Instella-3B-Instruct: amd/Instella-3B-Instruct, Final Instruction-tuned checkpoint.
Datasets#
Second stage pre-training GSM8k synthetic dataset: amd/Instella-GSM8K-synthetic
The dataset consists of two splits: “train” and “train_119K”.
For Instella-3B model second stage pre-training we used the “train_119K” split, which is a subset of the larger “train” split.
Code#
Github: AMD-AIG-AIMA/Instella
Please refer to the following blogs to get started with using these techniques on AMD GPUs:
Bias, Risks, and Limitations#
The models are being released for research purposes only and are not intended for use cases that require high levels of factuality, safety critical situations, health, or medical applications, generating false information, facilitating toxic conversations.
Model checkpoints are made accessible without any safety promises. It is crucial for users to conduct comprehensive evaluations and implement safety filtering mechanisms as per their respective use cases.
It may be possible to prompt the model to generate content that may be factually inaccurate, harmful, violent, toxic, biased, or otherwise objectionable. Such content may also get generated by prompts that did not intend to produce output as such. Users are thus requested to be aware of this and exercise caution and responsible thinking when using the model.
Multi-lingual abilities of the models have not been tested and thus may misunderstand and generate erroneous responses across different languages.
License#
The Instella-3B models are licensed for academic and research purposes under a ResearchRAIL license.
The amd/Instella-GSM8K-synthetic dataset used in second stage pre-training is built with Qwen2.5-72B-Instruct, and is licensed for academic and research purposes under a ResearchRAIL license. Refer to the LICENSE and NOTICES in the amd/Instella-GSM8K-synthetic dataset card files for more information.
Refer to the LICENSE and NOTICES files for more information.
Contributors#
Core contributors: Jiang Liu, Jialian Wu, Xiaodong Yu, Prakamya Mishra, Sudhanshu Ranjan, Zicheng Liu
Contributors: Chaitanya Manem, Yusheng Su, Pratik Prabhanjan Brahma, Gowtham Ramesh, Ximeng Sun, Ze Wang, Emad Barsoum
Citations#
Feel free to cite our Instella-3B models:
@misc{Instella,
title = {Instella: Fully Open Language Models with Stellar Performance},
url = {https://huggingface.co/amd/Instella-3B},
author = {Jiang Liu, Jialian Wu, Xiaodong Yu, Prakamya Mishra, Sudhanshu Ranjan, Zicheng Liu, Chaitanya Manem, Yusheng Su, Pratik Prabhanjan Brahma, Gowtham Ramesh, Ximeng Sun, Ze Wang, Emad Barsoum},
month = {March},
year = {2025}
}
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.