Instella-VL-1B: First AMD Vision Language Model#

As part of AMD’s newly released Instella family we are thrilled to introduce Instella-VL-1B, the first AMD vision language model for image understanding trained on AMD Instinct™ MI300X GPUs. Our journey with Instella-VL builds upon our previous 1-billion-parameter language models, AMD OLMo SFT. We further extend the language model’s visual understanding abilities by connecting it with a vision encoder (which is initialized from CLIP ViT-L/14-336). During training, we jointly finetune vision encoder and language model with vision-language data in three stages: Alignment, Pretraining and Supervised-Finetuning (SFT).
To build Instella-VL-1B, we created new data mixtures for both pretraining and SFT stages by combining LLaVA, Cambrian, Pixmo and other datasets. Specifically, we enrich the model’s ability of document understanding by adopting richer document-related dataset such as M-Paper, DocStruct4M and DocDownstream. With our new pretraining dataset (7M examples) and SFT dataset (6M examples), our Instella-VL-1B significantly outperforms fully open-source models of similar sizes (such as LLaVa-OneVision, MiniCPM-V2, etc.) on both general vision-language tasks and OCR-related benchmarks. It outperforms the open-weight model InternVL2-1B on general benchmarks and achieves comparable results on OCR-related benchmarks.
Adapted, and optimized for our hardware and model architecture from the LLaVA codebase and trained exclusively with publicly available datasets, Instella-VL-1B represents our commitment to advancing open-source AI technology in multi-modal understanding with AMD MI300X GPUs. In line with our commitment to open source, we are sharing not only the model weights but also detailed training configurations, datasets, and code. This enables the AI community to easily collaborate, replicate, and build upon our work, fostering innovation and accelerating progress.
In this blog you will learn about the Instella-VL-1B vision-language model (VLM) architecture, and the model’s training strategy and data. The blog discusses our open source reproducible vision of sharing the Instella-VL-1B, and the model optimization within the AMD ROCm ecosystem. The blog will also provide you with detailed results of benchmarking the Instella-VL-1B vision-language model (VLM) with other models. Follow the Links/Additional Resources section to get started with using Instella-VL model. We invite the AI community to explore its capabilities, provide valuable feedback, and contribute to its continued development.
Key Takeaways#
Announcing Instella-VL-1B, a vision language model trained on AMD Instinct MI300X GPUs.
Instella-VL-1B outperforms fully open-source models (e.g. LLaVa-OneVision, MiniCPM-V2) and many open-weight (e.g. InternVL2-1B, Deepseek-VL) with similar model scale on average general benchmarks (including GQA, ScienceQA, MMBench and so on) and on par with InternVL2 for OCR related benchmarks such as AI2D, DocVQA, Infographic-VQA, ChartQA.
Fully open source and Reproducible: Fully open-source release of model weights, training configurations, datasets, and code, fostering innovation and collaboration within the AI community.
ROCm compatible training optimizations: Leveraging techniques like FlashAttention-2, Torch.Compile, and DeepSpeed Stage 2/3 hybrid parallelism for distributed training.
Our motivation for building Instella-VL family of models is twofold:
Demonstrate Training Capabilities of AMD Instinct GPUs: By successfully training Instella-VL-1B from the ground up on these accelerators, we demonstrate their effectiveness and scalability for demanding AI workloads, establishing AMD hardware as a compelling alternative in the AI hardware market.
Advancing Open-Source AI: We’re furthering our commitment to open-source AI by making the model fully transparent. Beyond sharing the model weights and datasets, we are also providing our training codebase, environment and hyperparameters for the community to reproduce our results. This full transparency allows the AI community to understand, replicate, and build upon our work.
Instella-VL-1B#
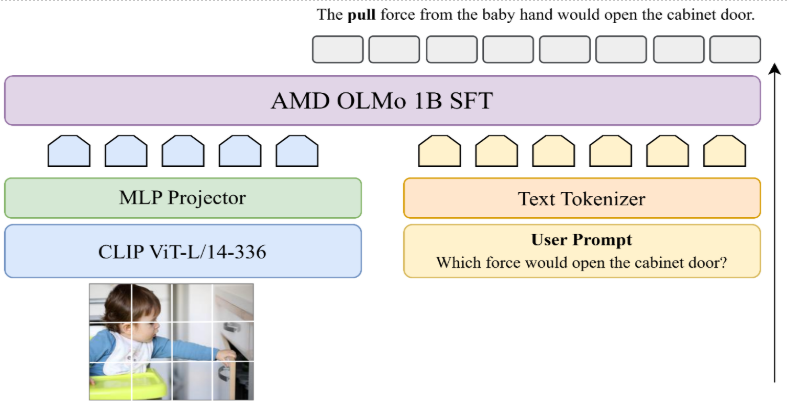
Figure 1: Instella-VL-1B network architecture#
Instella-VL-1B is a 1.5B parameter multimodal model trained on AMD Instinct MI300X GPUs, combining a 300M parameter vision encoder and a 1.2B parameter language model.
Model Architecture#
The model architecture integrates three key components as seen in Figure 1: a Vision Encoder using CLIP ViT-L/14@336 architecture featuring 24 layers, 16 attention heads and 1024 hidden size. The Language Model is based on AMD OLMo 1B SFT with 16 layers, 16 attention heads, and 2048 hidden size, and a Projector consisting of a 2-layer MLP designed to map the visual outputs to text tokens.
Hardware and Training Infrastructure#
Training was conducted with up to 4 nodes, totaling 32 GPUs, with each compute node comprising 8 AMD Instinct MI300X GPUs. Our training pipeline is based on an open-source LLaVA-NeXT codebase, which we adapted and optimized specifically for our hardware configuration and model architecture. For in-depth details regarding training hyperparameters and model inference, please refer to our Hugging Face model card and Github repository.
Datasets#
We build our training data with a mixture of LlaVa-OneVision-Data, Pixmo, mPLUG, M3IT, Cambrian, Cauldron and some small datasets. To ensure data diversity in different stages of training, we use a diverse collection of datasets from different domains ranging from general image-text caption pairs, OCR, Science, Math and Reasoning, Tables, Charts, Plots, and miscellaneous. For alignment stage, we use 558K examples from BLIP558K. The full list of datasets across Pretraining and Instruction tuning along with their domains and number of examples are listed below in Tables 1 and 2:
| Domain | Datasets | Num of Examples |
|---|---|---|
| Image Captions | BLIP150K, COCO118K, CC3M-Recap, Pixmo_Cap | 3.52M |
| OCR | SynthDog_EN, SynthDog_ZH, UReader, ART, COCO-Text, HierText, Uber-Text, TextOCR, OpenVINO, MLT-17 | 913K |
| Documents | DocVQA, DocStruct4M | 410K |
| Table, Chart, and Plot | Chart2Text, UniChart, PlotQA, WidgetCaption, Screen2Words, SciGraphQA-295K, Paper2Fig100K, MMC Instruction, M-Paper | 1.97M |
| Text Only | Evol-Instruct-GPT-4 | 70K |
Training Recipe#
For training Instella-VL-1B model, we employed a training recipe similar to LlaVa-OneVision , where we trained our model in three stages: 1) Alignment stage for MLP warmup to establish initial connections between visual and language modalities, 2) Pre-training stage for developing robust multimodal representations across diverse domains, and finally 3) Instruction-tuning stage for enhancing the model’s ability to follow complex instructions and perform specific tasks, as shown in Figure 2.

Figure 2: Three-stage training process for Instella-VL-1B, progressing from Alignment with 558K image-text pairs to Pre-Training with 7M examples, and finally SFT with 6M resampled examples#
Stage 1: Alignment (MLP Warmup)#
In this stage, the focus is on warming up the Multi-Layer Perceptron (MLP) components of the model. This helps in mapping the visual output to the text input and sets a foundation for further learning.
Stage 2: Pretraining#
During this stage, the entire model undergoes pretraining using a Next-token prediction (NTP) objective on carefully curated datasets across multiple domains. Image Captions provide diverse real-world image-text pairs essential for building general vision-language understanding. We significantly expanded OCR training data to enhance text recognition capabilities and document formats for real-world applications. Document Understanding datasets were added to improve the model’s ability to interpret complex document layouts and answer content-related questions. Scientific and Technical Understanding datasets strengthen the model’s interpretation of technical visualizations and scientific figures, addressing growing academic and professional needs. Text-Only datasets maintain the language decoder’s capabilities. This diverse collection helps the model learn representations across different visual and textual domains, preparing it for various downstream tasks.
Stage 3: Instruction Tuning#
Instruction Tuning builds upon the pretraining foundation by enhancing the model’s instruction-following capabilities through tuning on domain-spanning datasets. General Vision-Language Tasks expand beyond basic image-caption pairs to include complex visual reasoning, question answering, and multimodal understanding tasks for real-world applications. Technical/Scientific Tasks emphasize charts, diagrams, and scientific figures to improve the model’s interpretation and reasoning abilities. OCR and Text Recognition datasets covering diverse scenarios refine the model’s understanding of numbers, legends, tables, and text. Document Analysis enhances OCR capabilities and document understanding, allowing the model to locate specific answers within documents or provide concise summaries by filtering non-essential information. Mathematical and Logical Reasoning datasets develop comprehensive capabilities in mathematics, geometry, and logical problem-solving. Based on error analysis, we oversampled specific training datasets (ScienceQA, AI2D, PMC-VQA, Cambrian, and TQA) by approximately twice to strengthen the model’s understanding of science-based and general reasoning questions.
Results#
| Model Name | Vision Encoder | Text Encoder | Num. Params | General Benchmarks | OCR, Chart and Doc Understanding | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Average | GQA | SQA | POPE | MM-Bench | SEED-Bench | MMMU | RealWorldQA | MMStar | Average | OCRBench | TextVQA | AI2D | ChartQA | DocVQA | InfoVQA | ||||
| Open Weight Models | |||||||||||||||||||
| DeepSeek-VL-1.3B | SigLIP | DeepSeek-LLM-1B | 1.4B | -- | -- | 64.52 | 85.80 | 64.34 | 65.94 | 28.67 | 50.20 | 38.30 | 42.28 | 41.40 | 57.54 | 51.13 | 47.40 | 35.70 | 20.52 |
| InternVL2-1B | InternViT | Qwen2-0.5B | 1B | 61.26 | 55.06 | 89.54 | 87.40 | 61.70 | 65.90 | 32.40 | 51.90 | 46.18 | 67.53 | 74.40 | 69.60 | 62.40 | 71.52 | 80.94 | 46.30 |
| InternVL2.5-1B | InternViT | Qwen2-0.5B-instruct | 1B | 65.26 | 56.66 | 93.90 | 89.95 | 68.40 | 71.30 | 35.60 | 58.30 | 47.93 | 71.15 | 74.20 | 72.96 | 67.58 | 75.76 | 82.76 | 53.62 |
| Open Weight, Open Data Models | |||||||||||||||||||
| TinyLLaVA-2.4B | SigLIP | Gemma | 2.4B | 56.84 | 61.58 | 64.30 | 85.66 | 58.16 | 63.30 | 32.11 | 52.42 | 37.17 | 30.94 | 28.90 | 47.05 | 49.58 | 12.96 | 25.82 | 21.35 |
| TinyLLaVA-1.5B | SigLIP | TinyLlama | 1.5B | 53.06 | 60.28 | 59.69 | 84.77 | 51.28 | 60.04 | 29.89 | 46.67 | 31.87 | 32.85 | 34.40 | 49.54 | 43.10 | 15.24 | 30.38 | 24.46 |
| LLaVA-OneVision-1B | SigLIP | Qwen2-0.5B | 0.9B | 54.29 | 57.95 | 59.25 | 87.17 | 44.60 | 65.43 | 30.90 | 51.63 | 37.38 | 53.92 | 43.00 | 49.54 | 57.35 | 61.24 | 71.22 | 41.18 |
| MiniCPM-V-2 | SigLIP | MiniCPM-2.4B | 2.8B | -- | -- | 76.10 | 86.56 | 70.44 | 66.90 | 38.55 | 55.03 | 40.93 | 61.04 | 60.00 | 74.23 | 64.40 | 59.80 | 69.54 | 38.24 |
| Instella-VL-1B | CLIP | AMD OLMO 1B SFT | 1.5B | 62.62 | 61.52 | 83.74 | 86.73 | 69.17 | 68.47 | 29.30 | 58.82 | 43.21 | 67.50 | 67.90 | 71.23 | 66.65 | 72.52 | 80.30 | 46.40 |
We use lmms-eval to evaluate model performance. As shown in Table 3, Instella-VL-1B demonstrates better performance compared to fully open-source models, with substantial margins across key benchmarks. Specifically, it achieves ⬆️5.78% higher General Benchmarks Average (62.62% vs 56.84%) over TinyLLaVA-2.4B despite only using 62.5% parameters. In OCR, Chart and Document Understanding tasks, Instella-VL-1B shows even more impressive gains, with 67.50 vs 30.94 compared to TinyLLaVA-2.4B and ⬆️6.46% improvement (67.50% vs 61.04%) over MiniCPM-V-2.
When compared to open-weight models like InternVL2.5-1B, Instella-VL-1B maintains competitive performance, achieving comparable scores in both general benchmarks (62.62 vs 65.26) and document understanding tasks (67.50 vs 71.15), while matching the parameter efficiency at 1-1.5B parameters.
Summary#
The release of Instella-VL-1B represents a significant milestone as AMD’s first vision language model, demonstrating the capabilities of AMD Instinct MI300X GPUs for large-scale vision-language training. Outperforming comparable fully open-source models while remaining competitive with open-weight alternatives. Instella-VL-1B showcases the effectiveness of our training recipe with carefully curated publicly available datasets.
By fully open-sourcing this model—including weights, training/dataset details, and code—we aim to foster innovation and collaboration within the AI community. We believe that transparency and accessibility are key drivers of progress in AI research. We invite developers, researchers, and AI enthusiasts to explore Instella-VL-1B and contribute to its ongoing improvement.
We will continue enhancing the models across multiple dimensions, including multi-image understanding, visual reasoning ability, and video understanding capabilities. Additionally, we will scale up both the model and dataset while exploring diverse architectural approaches. Stay tuned for more exciting blogs on the Instella-VL family, its features and capabilities!
Links / Additional resources#
Model Cards: Hugging Face: amd/Instella-VL-1B
Code: Github: AMD-AIG-AIMA/InstellaVL
Please refer to the following blogs to get started with using these techniques on AMD GPUs:
Bias, Risks, and Limitations#
The models are being released for research purposes only and are not intended for use cases that require high levels of factuality, safety critical situations, health, or medical applications, generating false information, facilitating toxic conversations.
Model checkpoints are made accessible without any safety promises. It is crucial for users to conduct comprehensive evaluations and implement safety filtering mechanisms as per their respective use cases.
It may be possible to prompt the model to generate content that may be factually inaccurate, harmful, violent, toxic, biased, or otherwise objectionable. Such content may also get generated by prompts that did not intend to produce output as such. Users are thus requested to be aware of this and exercise caution and responsible thinking when using the model.
Multi-lingual abilities of the models have not been tested and thus may misunderstand and generate erroneous responses across different languages.
License#
The Instella-VL-1B model is licensed for academic and research purposes under a ResearchRAIL license.
Refer to the LICENSE and NOTICES files for more information.
Contributors#
Core contributors: Ximeng Sun, Aditya Kumar Singh, Gowtham Ramesh, Zicheng Liu
Contributors Pratik Prabhanjan Brahma, Ze Wang, Jiang Liu, Jialian Wu, Prakamya Mishra, Xiaodong Yu, Yusheng Su, Sudhanshu Ranjan, Emad Barsoum
Citations#
Feel free to cite our Instella-VL-1B model:
@misc{Instella-VL-1B,
title = {Instella-VL-1B: First AMD Vision Language Model},
url = {https://huggingface.co/amd/Instella-VL-1B},
author = {Ximeng Sun, Aditya Singh, Gowtham Ramesh, Jiang Liu, Ze Wang, Sudhanshu Ranjan, Pratik Prabhanjan Brahma, Prakamya Mishra, Jialian Wu, Xiaodong Yu, Yusheng Su, Emad Barsoum, Zicheng Liu},
month = {March},
year = {2025}
}
Disclaimers#
Third-party content is licensed to you directly by the third party that owns the content and is not licensed to you by AMD. ALL LINKED THIRD-PARTY CONTENT IS PROVIDED “AS IS” WITHOUT A WARRANTY OF ANY KIND. USE OF SUCH THIRD-PARTY CONTENT IS DONE AT YOUR SOLE DISCRETION AND UNDER NO CIRCUMSTANCES WILL AMD BE LIABLE TO YOU FOR ANY THIRD-PARTY CONTENT. YOU ASSUME ALL RISK AND ARE SOLELY RESPONSIBLE FOR ANY DAMAGES THAT MAY ARISE FROM YOUR USE OF THIRD-PARTY CONTENT.