AI Blogs - Page 2#

Accelerating Diffusers and xDiT Image Generation with MXFP4 using AMD Quark on AMD Instinct™ MI350 GPUs
Accelerate Diffusers and xDiT FLUX.1-dev image generation on AMD Instinct MI350 GPUs using AMD Quark MXFP4 quantization.

AgentKernelArena: Benchmarking AI Coding Agents for GPU Kernel Optimization on AMD Instinct GPUs
Explore how AI coding agents compare on real GPU kernel optimization with AgentKernelArena, AMD's open benchmarking arena for Instinct™ GPUs.
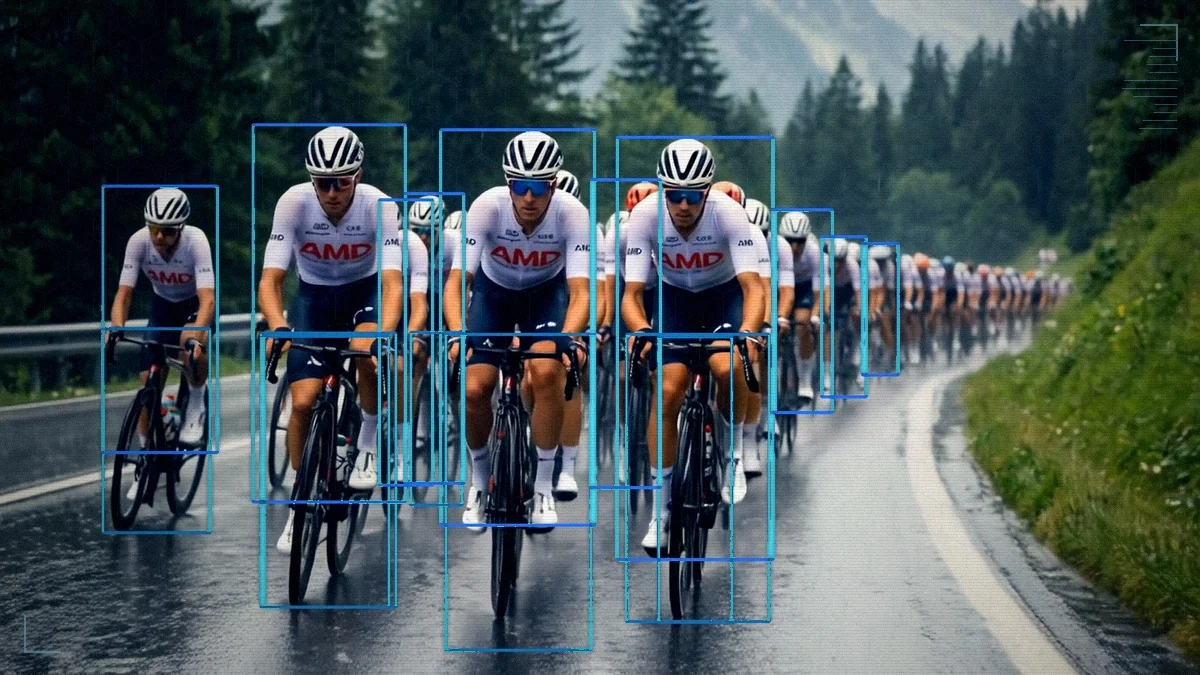
Building a GPU-Resident YOLO26 Object Detection Pipeline on the AMD Radeon™ AI PRO R9700 GPU
Build a GPU-resident object detection pipeline on AMD GPUs with rocDecode, DLPack, and MIGraphX. Frames stay in VRAM end to end.

Accelerating Large-Scale LLM Inference on AMD Instinct MI350X/MI355X with Eagle3 and AMD Quark
Learn how the AMD Quark team enables Eagle3 speculative decoding for Kimi-K2.5 and MiniMax-M2.5 on AMD Instinct MI355X GPUs with ROCm, vLLM, and InferenceX.

Accelerating LLM Inference on AMD GPUs with Low-Latency GEMMs
Learn how FlyDSL low-latency GEMMs speed up LLM decode on AMD GPUs with Split-K, K-slice parallelism, and an LDS-based pipeline.

OpenXLA and JAX - ROCm Support and the State of CI
Learn how OpenXLA and JAX run on AMD ROCm: what landed this year, how every PR is gated on real Instinct hardware, and how to get started.

Efficient GPU Utilization With Workload Pre-Emption in AMD Resource Manager
Learn how GPU workload pre-emption in AMD Resource Manager automatically reclaims idle GPU resources and improves cluster utilization.

MXFP6 and MXFP4 Mixed Precision for Accelerating Dense LLMs on AMD Instinct MI355X
W_MXFP4_A_MXFP6 quantization on AMD Instinct MI355X improves LLM throughput and latency while recovering accuracy versus MXFP4.

DP Attention and TBO for DeepSeek-V4 on MI355X
Learn how ATOM improves DeepSeek-V4 inference on AMD Instinct MI355X GPUs with DP Attention scheduling and Two-Batch Overlap.
Faster Kimi-K2.5-W4A8 Decoding with EAGLE3 on AMD Instinct™ MI325X
Add EAGLE3 speculative decoding and three MoE/FMHA kernel-tuning patches to Kimi-K2.5-W4A8 inference on AMD Instinct™ MI325X with SGLang, AITER, and FlyDSL.

A Practical Guide to Running LLMs on AMD Radeon™ GPUs
This guide describes how to run LLMs on AMD Radeon™ GPUs using a range of partner frameworks, tools, and runtimes, with step-by-step setup instructions and performance optimization tips.

Building and Deploying Custom hipBLASLt Libraries on AMD Instinct GPUs
Learn how to manage hipBLASLt environments with custom source builds, RPM/DEB packaging, and version switching on AMD Instinct GPUs.