Featured Posts

Reproducing the AMD MLPerf Inference v6.0 Submission Result
Provide instructions to potential customers and partners to verify our MLPerf Inference v6.0 submission result.

Utilizing AMD Instinct GPU Accelerators for Weather and Precipitation Forecasting with NeuralGCM
A showcase of how to run NeuralGCM, a hybrid GCM model, on AMD Instinct hardware, including an introduction, installation, inference, and plotting.

FP8 GEMM Optimization on AMD CDNA™4 Architecture
Learn how to build high-performance FP8 GEMM kernels on AMD CDNA™4 GPUs using MFMA, LDS swizzling, and double-buffering.

ROCm 7.2: Smarter, Faster, and More Scalable for Modern AI Workloads
we highlight the latest ROCm 7.2 enhancements for AMD Instinct GPUs, designed to boost AI and HPC performance

Deploy and Customize AMD Solution Blueprints
Learn how to deploy and customize AMD Solution Blueprints — from default deployment to swapping and reusing AMD Inference Microservices across multiple blueprints.

AMD Instinct™ GPUs MLPerf Inference v6.0 Submission
In this blog, we share the technical details of how we accomplish the results in our MLPerf Inference v6.0 submission.

Leveraging AMD AI Workbench to Scale LLM Inference for Optimal Resource Utilization
Learn how to use the AMD AI Workbench GUI and AIM Engine CLI capabilities to enable and configure autoscaling for your AI workloads.

Training a Robotic Arm Using MuJoCo and JAX on AMD Hardware with ROCm™
A complete guide to training an RL-based pick-and-lift robotic arm in MuJoCo with JAX, running on AMD hardware via ROCm.

Elevate Your LLM Inference: Autoscaling with Ray, ROCm 7.0.0, and SkyPilot
Learn how to use multi-node and multi-cluster autoscaling in the Ray framework on ROCm 7.0.0 with SkyPilot

Building Robotics Applications with Ryzen AI and ROS 2
This blog post gives a walkthrough of how to deploy a robotics application on the AI PC integrated with ROS - the robot operating system. We showcase Ryzen AI CVML Library to do perception tasks like depth estimation and develop a custom ROS 2 node which allows easy integration with the ROS ecosystem and standard components.

Quickly Developing Powerful Flash Attention Using TileLang on AMD Instinct MI300X GPU
Learn how to leverage TileLang to develop your own kernel. Explore the power to fully utilize AMD GPUs

Accelerating llama.cpp on AMD Instinct MI300X
Learn more about the superior performance of llama.cpp on Instinct platforms.

Programming Tensor Descriptors in Composable Kernel (CK)
Learn how to use TensorDescriptor in Composable Kernel (CK) to manage multi-dimensional data layouts and write efficient GPU kernels on AMD GPUs.
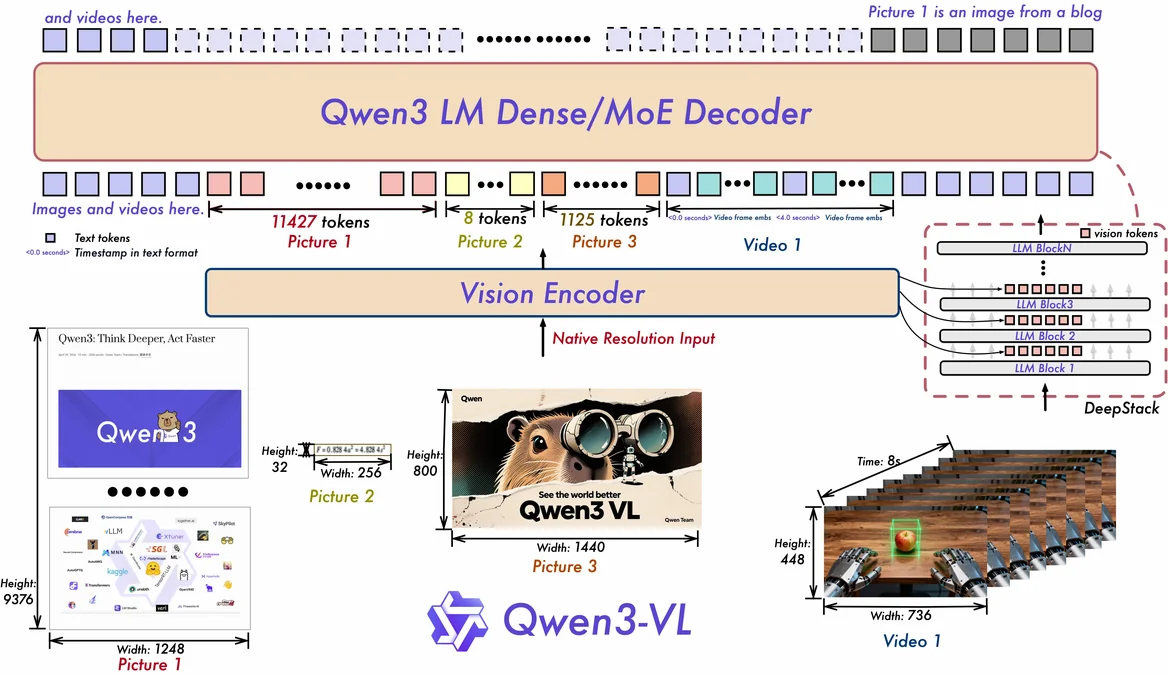
Engineering Qwen-VL for Production: Vision Module Architecture and Optimization Practices
Explore how to optimize Qwen-VL for production on AMD Instinct MI308X GPUs with ROCm, from vision module architecture to kernel fusion and deployment.

GROMACS on AMD Instinct GPUs: A Complete Build Guide
Build GROMACS with HIP, UCX, and OpenMPI on AMD MI300X/MI355X — covering bare metal, Apptainer, and Docker deployments.

Accelerating Kimi-K2.5 on AMD Instinct™ MI300X: Optimizing Fused MoE with FlyDSL
Optimize Kimi-K2.5 on AMD MI300X using FlyDSL for fused MoE kernel acceleration. Achieve faster TTFT, TPOT, and throughput with our step-by-step optimization guide.

AMD Device Metrics Exporter v1.4.2: Enhanced Observability, Deeper RAS Insights, and Smarter GPU Telemetry for Modern HPC & AI Clusters
Struggling with GPU bottlenecks? Learn how AMD DME v1.4.2 uncovers power, thermal, and RAS issues with actionable, production-ready telemetry.

Multi-Node Distributed Inference for Diffusion Models with xDiT
Follow a tutorial on multi-node video generation with diffusion models, covering scaling considerations and a practical Docker-based example.

Agentic Diagnosis for LLM Training at Scale
Explore how AI agents diagnose LLM training incidents — from RCCL hangs to throughput regressions — in one prompt with MaxText-Slurm.

MaxText-Slurm: Production-Grade LLM Training with Built-In Observability
MaxText-Slurm: A unified launch system for production-grade LLM training with observability on AMD GPU clusters.
Stay informed
- Subscribe to our RSS feed (Requires an RSS reader available as browser plugins.)
- Signup for the ROCm newsletter
- View our blog statistics
- View the ROCm Developer Hub
- Report an issue or request a feature
- We are eager to learn from our community! If you would like to contribute to the ROCm Blogs, please submit your technical blog for review at our GitHub. Blog creation can be started through our GitHub user guide.